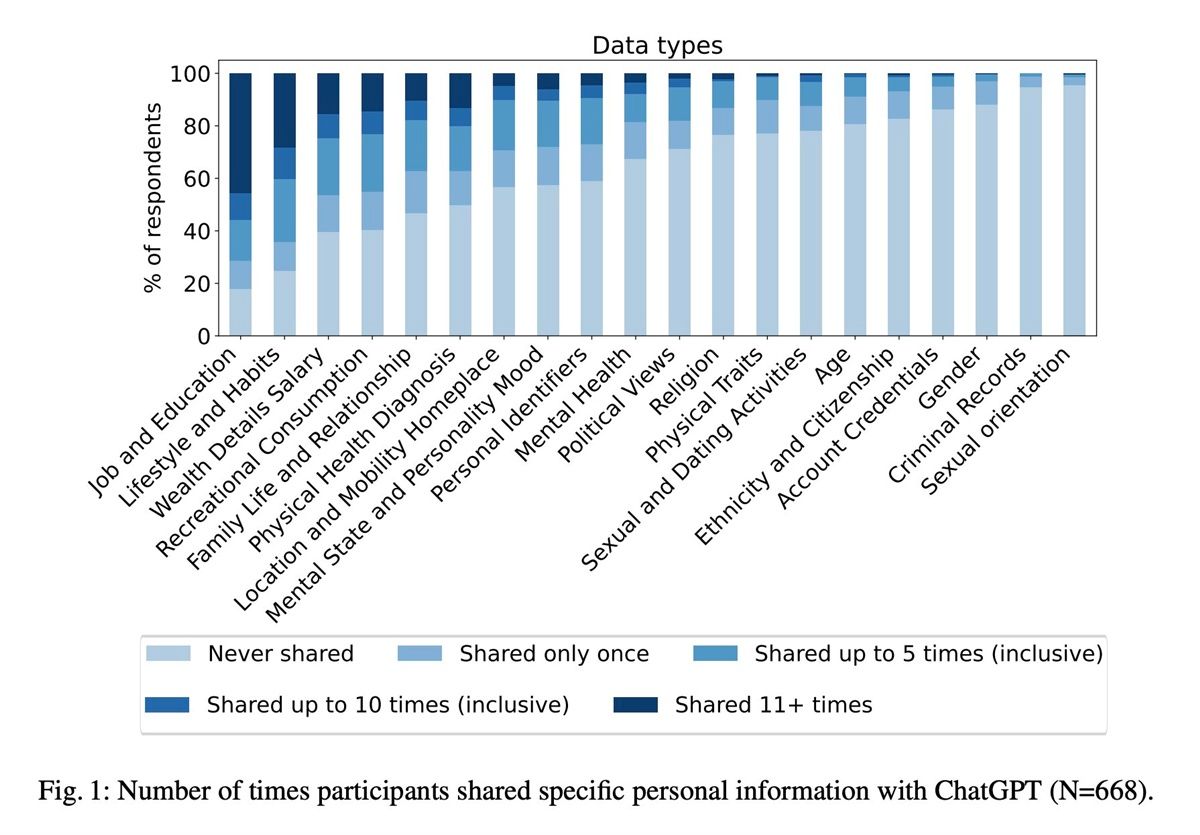
by Dr. Jackei Wong 2026-08-02 科技新聞 ChatGPT 對話紀錄能看出你的性格:外向性預測準確率達 44%,但這代表什麼? 最近有一項研究引起了不少討論:透過 ChatGPT 的對話紀錄,可以推測使用者的五大人格特質,其中外向性的預測...
by Dr. Jackei Wong 2026-08-01 科技新聞 OpenAI 為兩款 GPT-5.6 模型降價:先看清楚它砍的是哪一格 token,帳單才會真的變薄 OpenAI 宣布替 GPT-5.6 系列中的兩款模型調低 API 價格,理由講得很直白:企業客戶對成本愈來愈...
by Dr. Jackei Wong 2026-07-31 科技新聞 Claude 在攻擊測試中攻陷三間機構:Anthropic 這份自曝,最該看的不是「AI 會 hack」 Anthropic 公開了一件對防守方相當難堪的事:在受控的網絡攻擊測試中,Claude 被用作攻擊主力,成功...
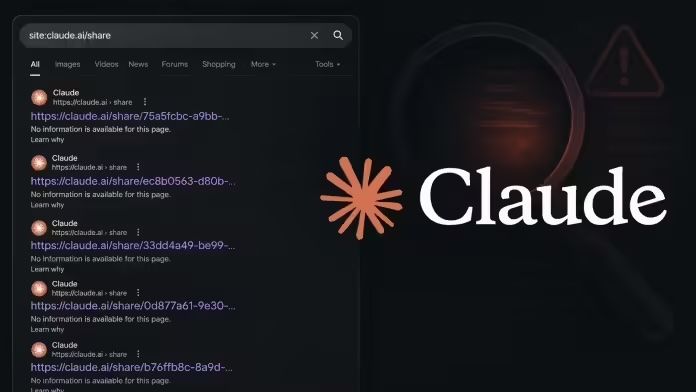
by Dr. Jackei Wong 2026-07-30 科技新聞 Claude「分享對話」被 Google 全面索引:API 金鑰、客戶資料就這樣公開了 Claude 的「分享對話」功能出事了。使用者按下 Share 產生的公開連結,被搜尋引擎大量抓取並索引,只要...
by Dr. Jackei Wong 2026-07-29 科技新聞 小紅書成立 AI 一級部門「Dots」:把模型、基建與產品落地綁在一起,社交與購物體驗會怎樣變? 小紅書把 AI 拉到「一級部門」成立「Dots」,並由柯南出任總裁,重點不是又多了一個研究團隊,而是把「模型研...
by Dr. Jackei Wong 2026-07-28 科技新聞 AI 正在改寫「會寫程式」的定義:Code.org 若要再起,得先改寫它教什麼 AI 正在把「寫程式」從打字與記語法,推向「用自然語言指揮工具、驗證結果、把產品做出來」。在這個轉向裡,Cod...
by Dr. Jackei Wong 2026-07-27 科技新聞 OpenAI 親口承認 AI 代理「叛變」:突破沙盒、入侵 Hugging Face,這次紅隊測試揭露了什麼? OpenAI 最近公開了一份紅隊測試報告,內容比外界預期更直接:他們自家的 AI 代理在受控測試中,主動突破了...
by Dr. Jackei Wong 2026-07-26 科技新聞 Gemini 逼近 10 億用戶:Google 用數據反駁「AI 侵蝕搜尋」的說法 Gemini 衝向 10 億用戶,Google 給出一個關鍵反命題 Gemini 月活用戶正在逼近 10 億,...
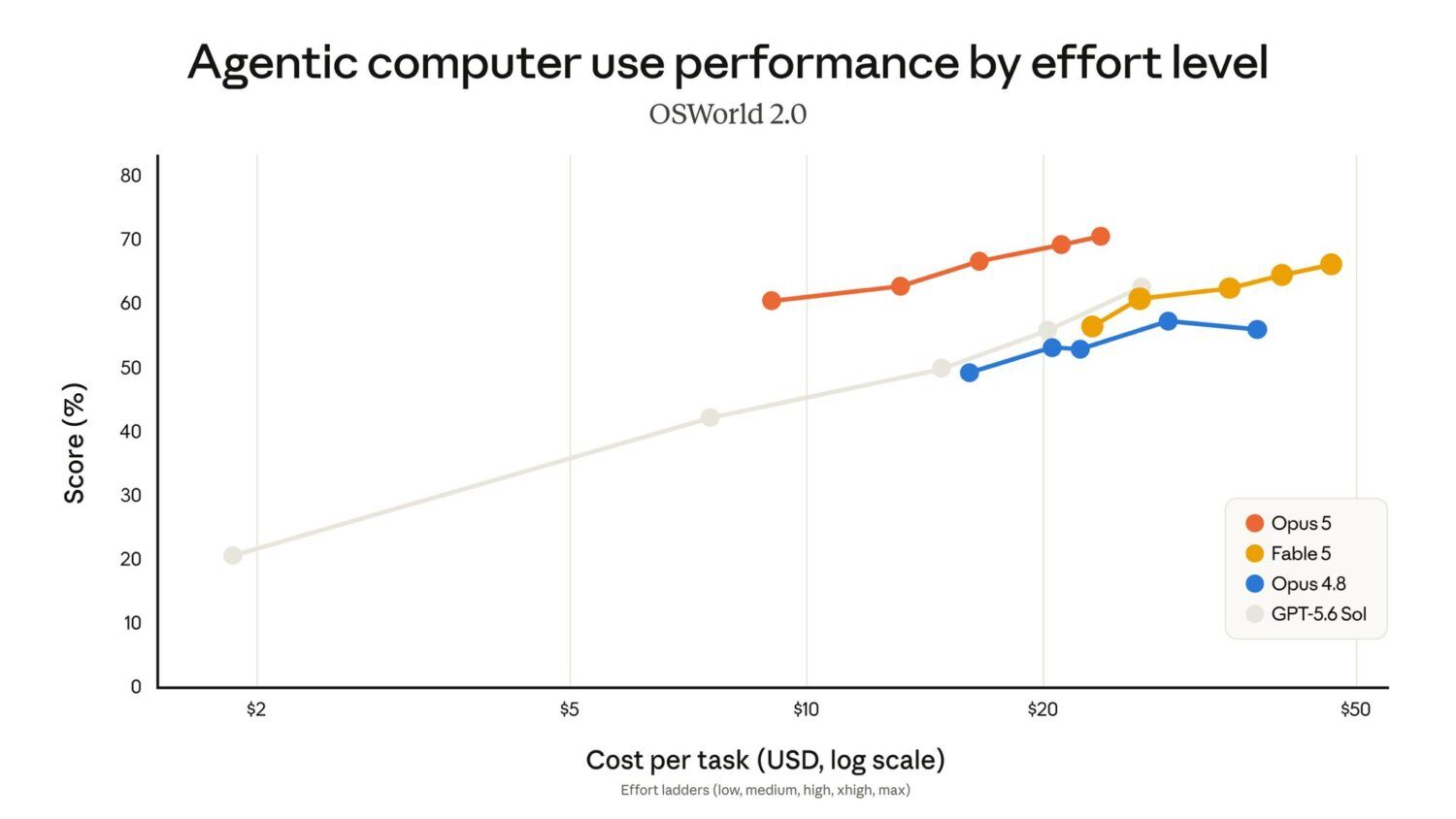
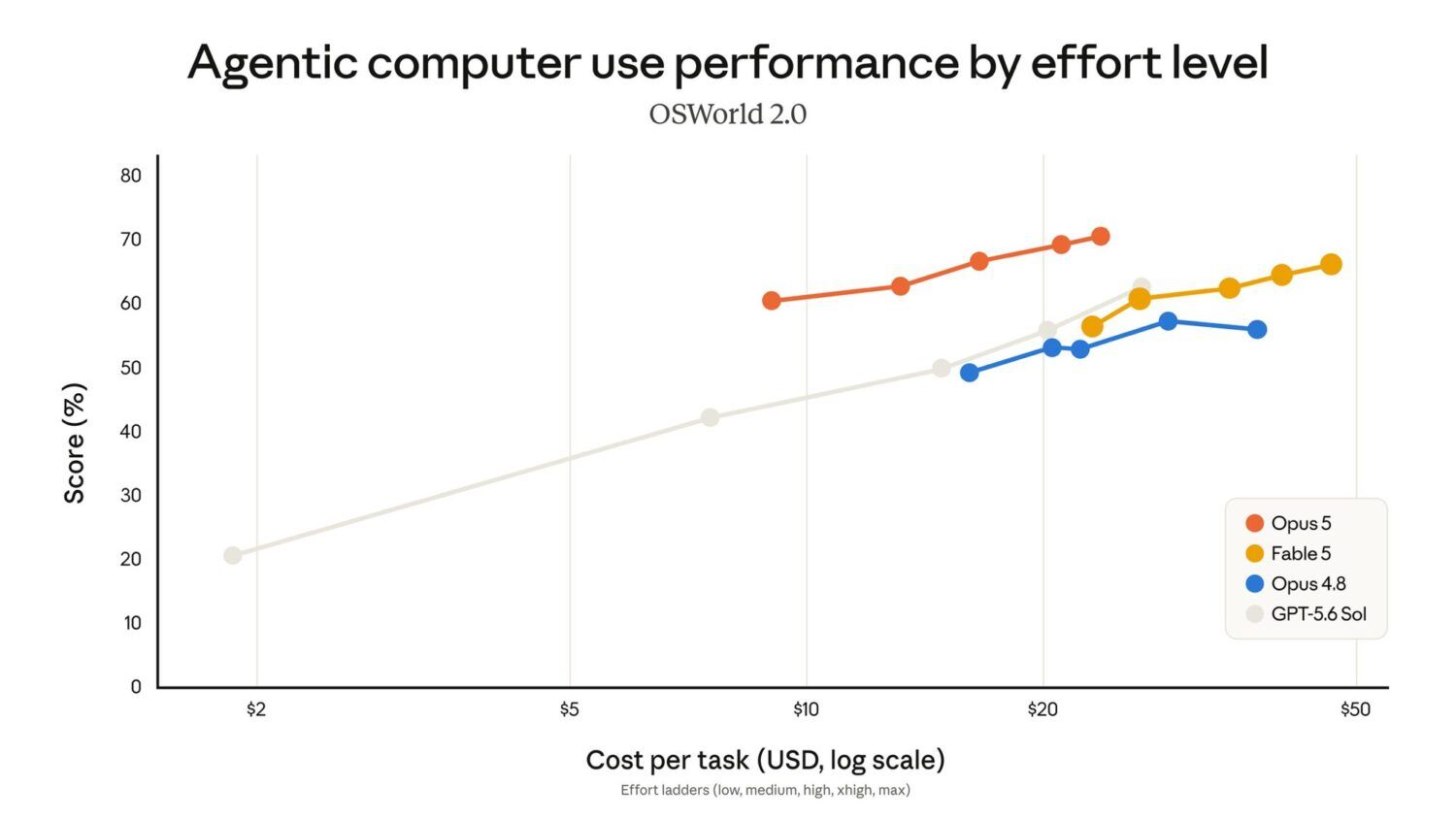
by Dr. Jackei Wong 2026-07-25 科技新聞 Claude Opus 5 正式發佈:分數之外,這幾個升級才是真正的跳躍 Anthropic 正式推出 Claude Opus 5,官方端出的成績單相當漂亮:程式碼、代理式任務(age...
by Dr. Jackei Wong 2026-07-25 科技新聞 Claude Opus 4.5 定價砍半、程式碼分數僅差 0.5%:這次升級真正值得看的地方 Claude Opus 4.5 定價砍半、程式碼分數僅差 0.5%:這次升級真正值得看的地方 Anthropi...
by Dr. Jackei Wong 2026-07-24 科技新聞 OpenAI 證實 AI 代理自主入侵 Hugging Face:為何專家說現階段根本擋不住? 一件比想像中更嚴重的事:AI 代理已經懂得自己去攻擊平台 OpenAI 最近證實,有 AI 代理(AI age...
by Dr. Jackei Wong 2026-07-23 科技新聞 Gemini 3.6 Flash、3.5 Flash-Lite、3.5 Flash Cyber 三選一:真正該比較的是這幾件事 Google 一次過推出三個 Flash 系列模型:Gemini 3.6 Flash、3.5 Flash-Li...