by Dr. Jackei Wong 2026-06-30 科技新聞 Google 盯上「情感型 AI」:Gemini 禁模仿人類情緒、青少年上線人設保護,對品牌與內容站意味著什麼? 當聊天式 AI 從「回答問題」走向「陪伴對話」,風險也跟著升級。Google 宣布限制 Gemini 模仿人類...
by Dr. Jackei Wong 2026-06-29 科技新聞 「MIT數學實錘、ChatGPT誘發AI精神病、14人死亡」是真的嗎?一次看懂傳言、風險與自保方法 「MIT數學實錘」這種說法,先從可驗證的地方開始 近期網路出現一種高度聳動的敘事:MIT 用數學證明 Chat...
by Dr. Jackei Wong 2026-06-28 科技新聞 跟 ChatGPT 愈聊愈笨?MIT 科學家罕見提前公開研究:真正風險可能不在「變笨」 最近「跟 ChatGPT 愈聊愈笨」的說法再度發酵,原因是一份由 MIT 研究團隊提前公開(尚未完成同儕審查)...
by Dr. Jackei Wong 2026-06-24 科技新聞 OpenAI一年燒掉340億美元:營收暴增三倍,仍補不回的錢坑在哪? OpenAI從未公開的審計財報外流,數字比外界想像更刺眼。2025年總支出達340億美元,營收只有約130億美...
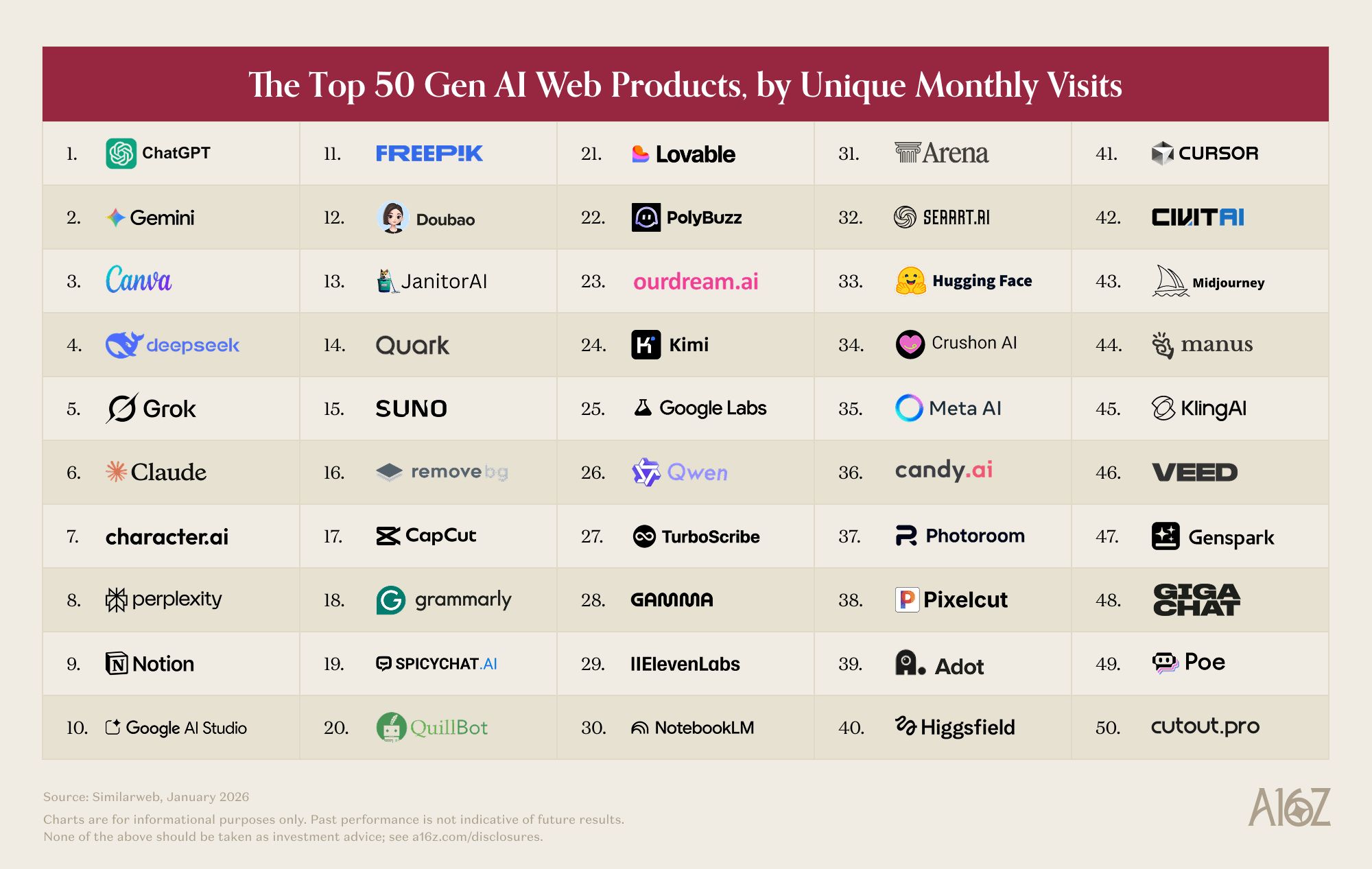
by Dr. Jackei Wong 2026-06-21 科技新聞 2026 年 3 月全球 100 大生成式 AI 消費應用榜單解析:誰在成長、誰在掉隊、下一波機會在哪? 2026 年 3 月全球 100 大生成式 AI 消費應用榜單解析 生成式 AI 已經從「新奇工具」快速走向日...
by Dr. Jackei Wong 2026-06-15 科技新聞 Claude Cowork、Chat、Code 怎麼選?三種生成式 AI 工作流模式全攻略,讓知識工作效率翻倍 生成式 AI 早就不只是「問答機器」,真正拉開效率差距的,是你能不能把它嵌進日常流程:從需求釐清、資料整理、產...
by Dr. Jackei Wong 2026-06-02 AI學堂-Youtube Gemini 一鍵美化 PPT 實測|Google Slides AI 生成簡報真係咁好用?|Google Gemini 教學 Gemini / Google Slides AI 開始支援一鍵美化 PPT、生成 infographic 及 cover slide。今次我用一份普通 AI 培訓 proposal 草稿做實測,看看它能否將 bullet points、raw data 和 timeline 變成更專業的簡報視覺,同時觀察它在中文字、可編輯性與資料準確性上的限制。
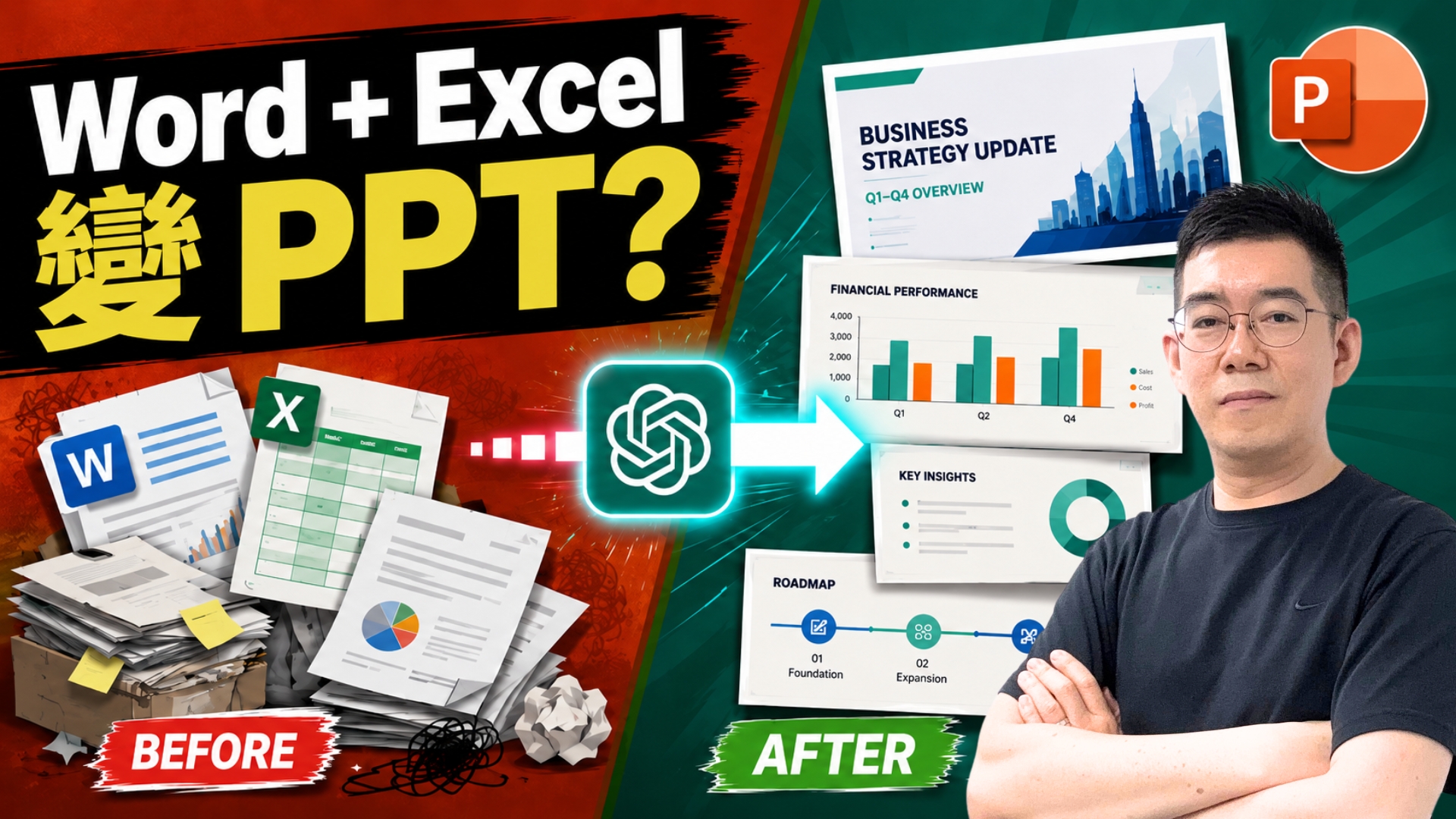
by Dr. Jackei Wong 2026-05-27 AI學堂-Youtube Word + Excel 直接出 PowerPoint?實測 ChatGPT 做完整簡報工作流,AI 生成 PPT 比想像中實用(PowerPoint AI 教學) 實測 ChatGPT for PowerPoint 能否真正融入 PowerPoint 工作流,由 Word、Excel 資料生成簡報初稿,到 AI 整 PPT、改稿、加入數據頁、roadmap slide,以及從管理層角度 review 成份簡報。
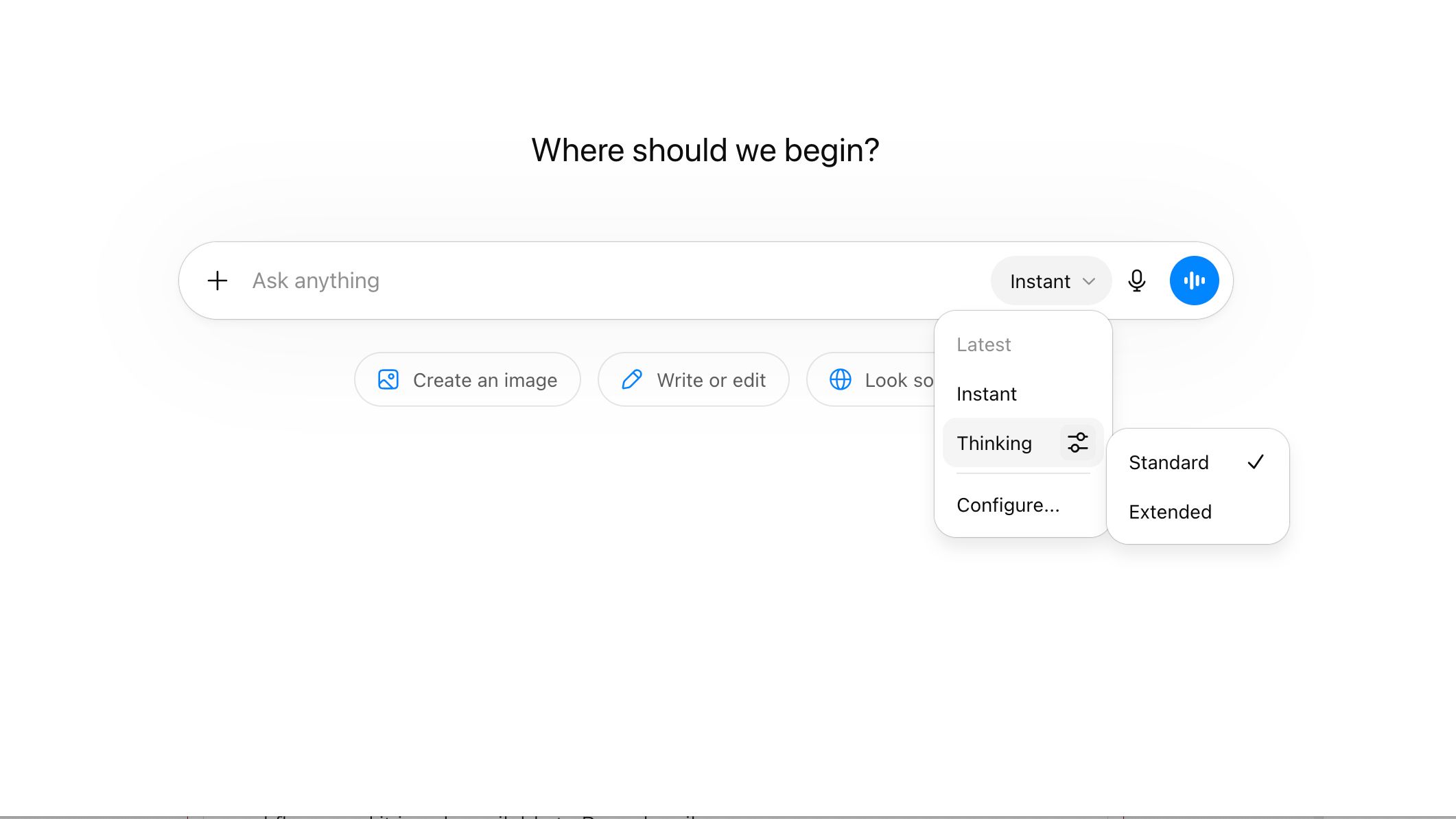
by Dr. Jackei Wong 2026-05-08 科技新聞 ChatGPT 把模型名稱收起來了:Instant、Thinking、Pro 其實在教你怎麼用 AI ChatGPT 最近把「模型選擇器」做了一次很關鍵的改版:你不再先看到一串模型代號,而是改用 Instant、...
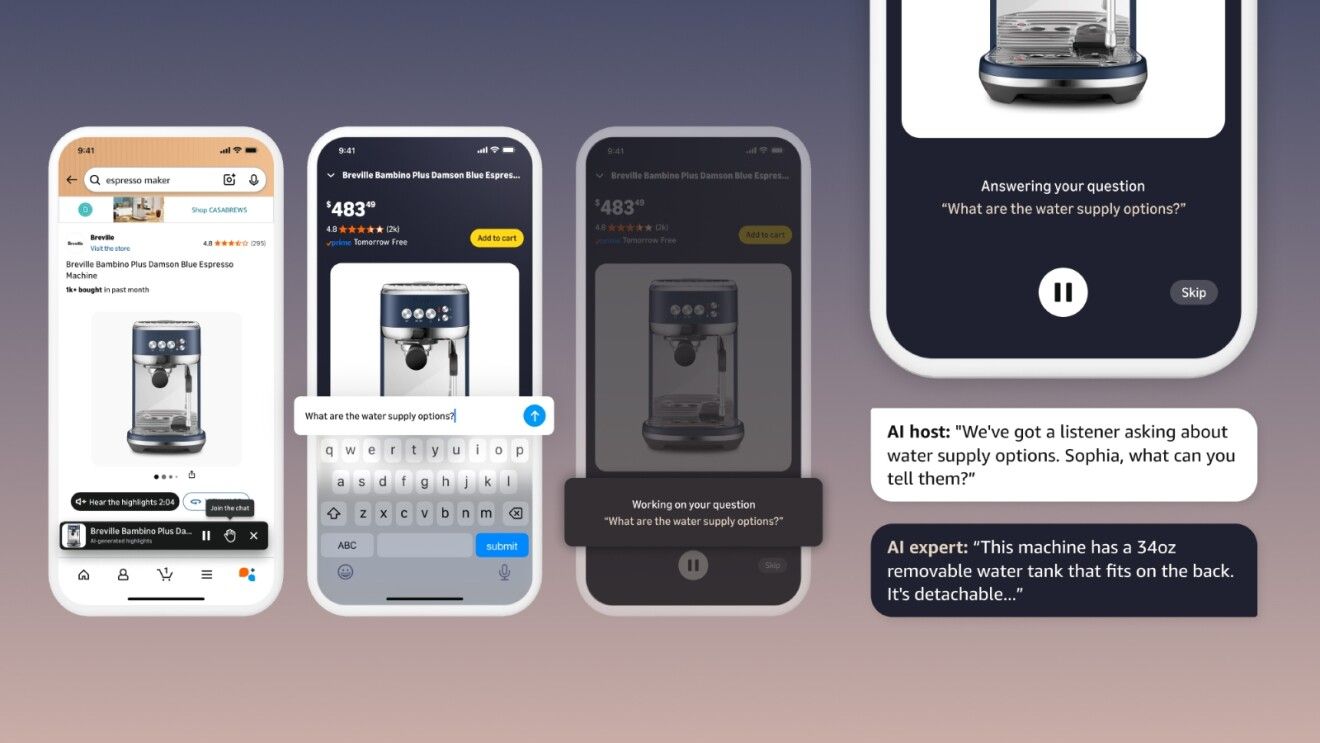
by Dr. Jackei Wong 2026-05-07 科技新聞 亞馬遜「Join the chat」把商品頁變成語音導購:真正改變的不是問答,而是你下單前的猶豫方式 亞馬遜在 4 月 30 日上線「Join the chat」AI 語音問答:你在商品詳情頁不用再翻規格、找 Q...
by Dr. Jackei Wong 2026-04-24 科技新聞 GPT-5.5 不是更會「回答」,而是更會「把程式工作做完」:OpenAI 這次真正的升級重點 OpenAI 正式發表 GPT-5.5,主打在編碼、電腦操作與深度研究等能力再升級,並開始向付費方案用戶開放,...
by Dr. Jackei Wong 2026-04-22 科技新聞 ChatGPT Images 2.0 上線後,最有感的不是「更會畫」:是文字排版終於能交付 ChatGPT Images 2.0 這次最明確的升級,是「精準度」與「文字排版」一起變得可用:你不再只是在抽...