
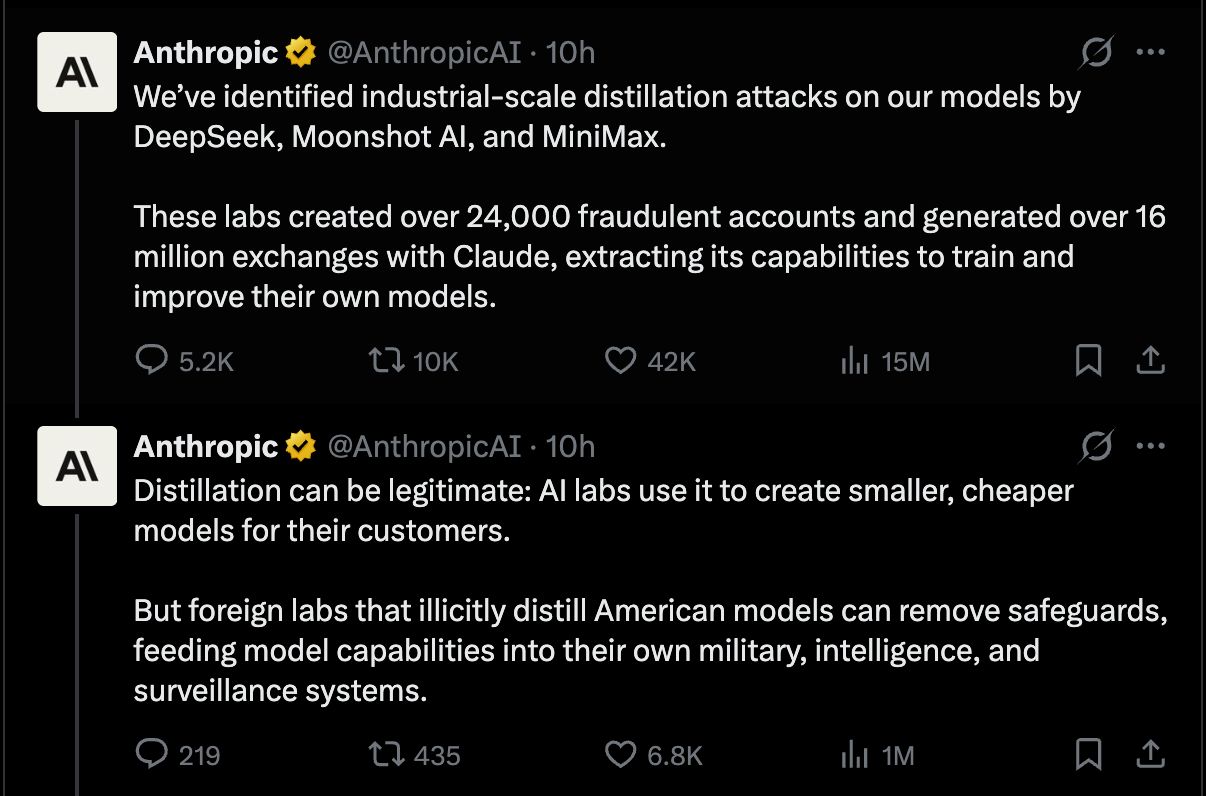
大型語言模型蒸餾正成為當前 AI 戰略版圖上的關鍵詞,特別是在中美大模型競爭與技術擴散的脈絡下。當我們討論中國大型語言模型能否「追上甚至超越」美國前沿模型時,蒸餾究竟是決定性武器,還是被誇大的助攻工具,是一個值得冷靜拆解的問題。 本文聚焦於一個核心提問:蒸餾對大型語言模型的真正影響有多大? 什麼是大型語言模型蒸餾?從「知識轉移」到「合成資料」 在工程實務中,「蒸餾」已遠遠超出教科書中狹義的知識蒸餾定義。如今談的大型語言模型蒸餾,大致包含以下幾層意義: 使用更強模型的輸出,去訓練較小或較弱的模型 大量生成高品質合成資料(synthetic data),再用來微調或後訓練 在特定能力上進行「能力搬運」,例如推理、Agent 行為、工具調用等 換句話說,蒸餾已經不只是「壓縮一個模型」,而更像是用算力把一部分模型能力轉成資料資產,再讓自己的模型去學。 在當前 LLM 開發流程中,蒸餾與合成資料的重要性體現在: 補足人類標註資料的成本與稀缺 快速試驗新能力(如長鏈推理、複雜工具編排) 讓中型模型在特定場景逼近或超越巨型模型表現 也因此,當談到中國大型語言模型的突飛猛進時,外界自然會把目光聚焦到:這些模型到底從美國前沿 API 蒸餾了多少能力? 蒸餾操作的真實規模:數十億還是數千億 Tokens? 近期有國際公司公開指出,多家中國實驗室透過...