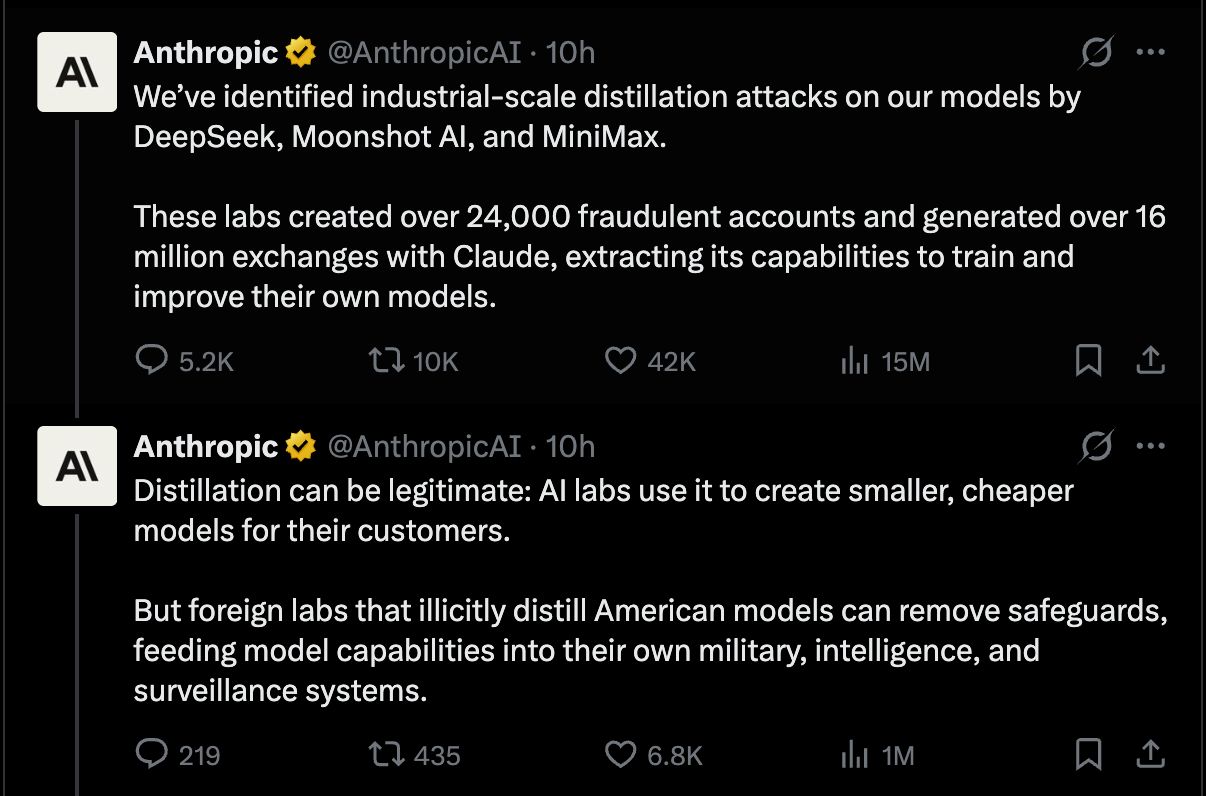
by Dr. Jackei Wong 2026-03-31 科技新聞 Gemini 模型蒸餾攻擊解析:十萬提示詞就能「複製」AI?企業該怎麼防 Gemini 模型蒸餾攻擊在吵什麼?先把「蒸餾」與「偷模型」分清楚 所謂「模型蒸餾(model distill...
by Dr. Jackei Wong 2026-03-06 科技新聞 大型語言模型蒸餾:中國大模型追趕美國實力、算力與RL的真實作用——深度解析蒸餾、合成資料與強化學習差距與全貌 大型語言模型蒸餾正成為當前 AI 戰略版圖上的關鍵詞,特別是在中美大模型競爭與技術擴散的脈絡下。當我們討論中國...