
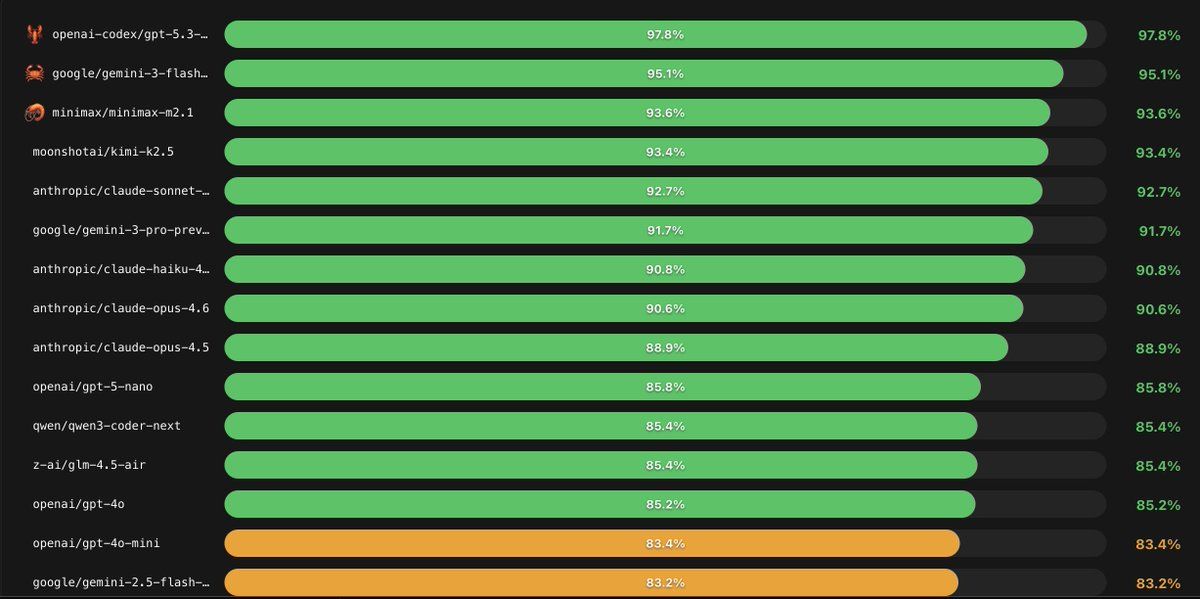
OpenClaw 釋出官方 Agent 成功率(success rate) 數據後,很多人第一個問題都是:「到底哪個模型最強?」但如果只把榜單當成冠軍賽排名,很容易選錯工具、甚至把 PoC 做到一半才發現成本、穩定性或安全性不合用。 這篇文章會用「如何讀懂成功率」為主線,帶你看 OpenClaw 類評測在說什麼、沒說什麼,以及不同使用情境該怎麼把數據轉成可落地的選型決策。 成功率到底測到什麼?它其實在測「把事情做完」的能力 一般聊天模型評估常看回答品質或知識正確性;但 Agent 評估(像 OpenClaw)更接近真實工作: 需要多步推理:拆解任務、規劃步驟、調整策略 需要工具使用:呼叫搜尋、瀏覽器、API、程式執行、檔案處理等 需要狀態管理:記住已做過什麼、避免重複、處理中斷與回復 因此「成功率」的直覺意義是:在固定環境與規則下,模型作為 Agent 能否把任務完整交付。對想做自動化工作流、客服助手、資料整理、內部營運工具的人來說,這比單輪問答更接近實戰。 為什麼榜單一公布,大家仍會得出相反結論?關鍵在你怎麼解讀「最強」 OpenClaw...