by Dr. Jackei Wong 2026-04-06 科技新聞 QuitGPT 運動崛起:人們為何抵制 ChatGPT?從政治倫理到「選擇權」的真正代價 QuitGPT 並不是一句情緒化的口號,而是一種「用腳投票」的使用者行動:有人刻意減少或停止使用 ChatGP...
by Dr. Jackei Wong 2026-04-04 科技新聞 Google Gemma 4 來了?離線跑 AI 為何成為新主流:效能、隱私與落地指南 「離線跑 AI」這件事,近一年從極客玩具快速變成企業與個人都在關注的部署選項。若你看到「Google Gemm...
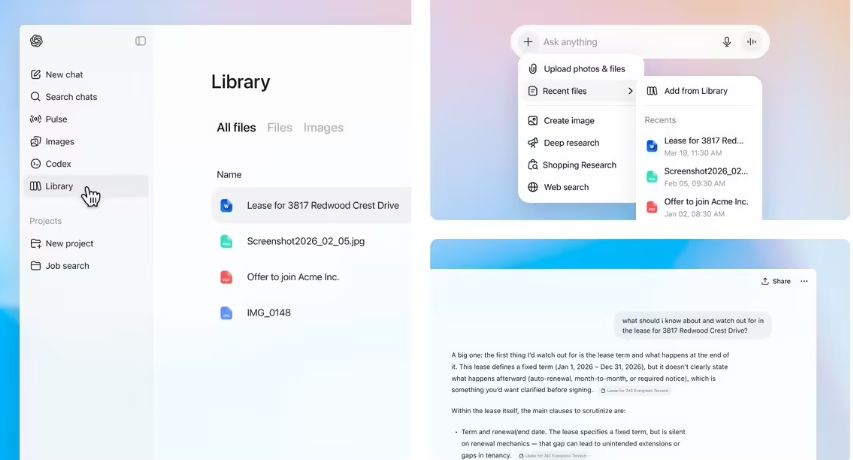
by Dr. Jackei Wong 2026-03-28 科技新聞 ChatGPT「圖庫」雲端功能上線:檔案影像自動保存、跨對話即取即用,工作流會怎麼變? ChatGPT 近期推出「圖庫」雲端功能,主打自動保存你在對話中產生或上傳的檔案與影像,並且能在不同對話間快速...