
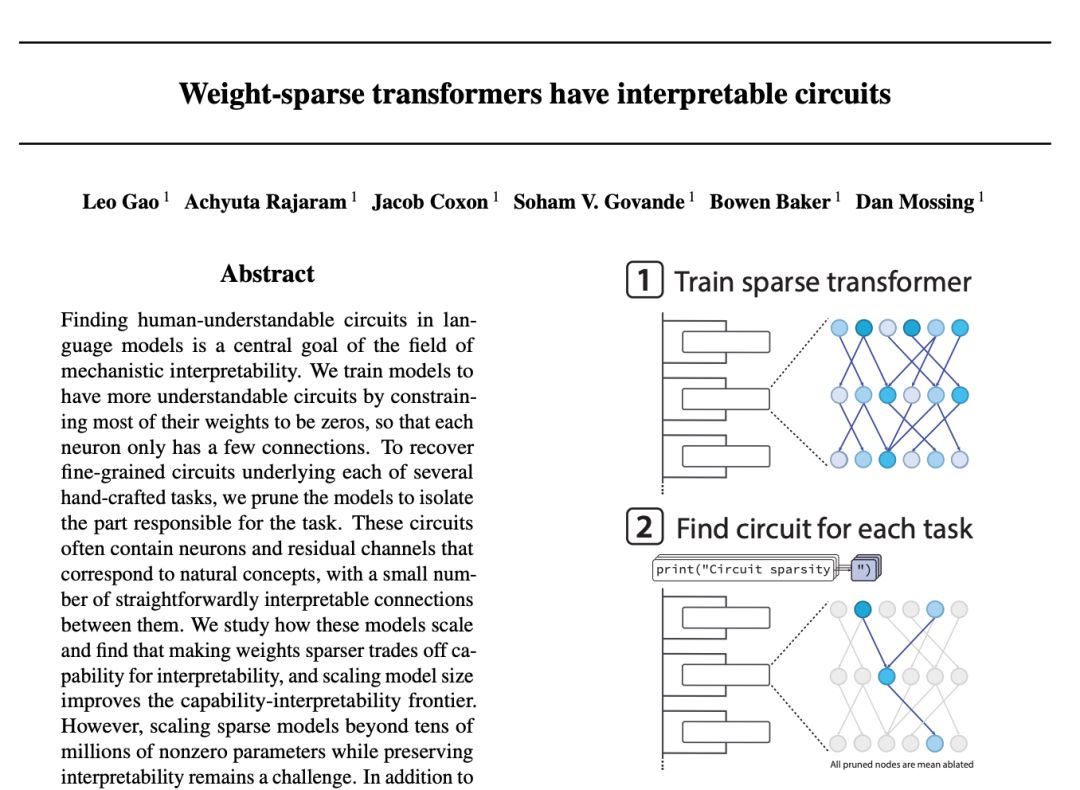
OpenAI推出Sparse Circuits研究 邁向可解釋AI時代 在人工智能快速發展的今日,AI模型的決策過程如同黑盒一般難以理解,這個問題日益成為業界的關鍵挑戰。OpenAI最近發表了一項突破性研究,透過「Sparse Circuits」(稀疏迴路)技術,嘗試揭開神經網絡的神秘面紗,為可解釋AI的未來鋪路。 Sparse Circuits的核心概念 Sparse Circuits是一種新穎的訓練方法,其核心思想在於將人工神經網絡的內部推理過程濃縮至有限的連接路徑中。與傳統的複雜模型不同,Sparse Circuits透過減少神經元之間的連接數量,使得整個模型結構變得更加簡潔易懂。這種方法使得研究人員能夠像閱讀電路圖般,清晰地觀察模型在執行特定任務時,究竟是哪些部分在發揮作用。 舉例而言,當模型需要在代碼中正確終止字符串時,研究人員可以精確定位負責此任務的神經網絡部分。這種微觀層級的理解,對於建立AI安全性和可信度至關重要。 機械論解釋性的革新方向 OpenAI的研究屬於「機械論解釋性」(Mechanistic Interpretability)這一新興領域。這個領域旨在通過分析AI模型的內部結構和運作機制,使人類能夠理解AI如何進行推理。與以往僅關注輸入輸出對應關係的方法不同,機械論解釋性深入模型內部,解析其算法原理。 為了實現這一目標,研究者採用了多種創新技術。其中「Sparse Autoencoder」(稀疏自編碼器)特別值得關注,它能將密集的內部表示轉換為高維度但稀疏的特徵基礎,使得AI模型內部的特徵變得更加單一化和易於理解。通過這種方法,研究人員成功從Claude 3 Sonnet等大型語言模型中提取出人類可理解的特徵,包括性別偏見、代碼錯誤等具體內容。 另一項重要技術是「Logit Lens」,它通過在Transformer的殘差流中應用Unembedding矩陣,使研究人員能夠觀察模型在各個層級的預測如何逐步演變。這種可視化方法讓我們得以看見AI思維的「進化過程」。 實證案例與突破 OpenAI和其他主要AI研究機構已經在實踐中取得了顯著成果。在GPT-2 small模型上,研究人員成功識別出處理「Greater Than」任務的迴路。這項工作涉及模型理解諸如「戰爭持續了從1732年到17年」這樣的提示,並輸出大於32的數字。透過識別關鍵神經元和它們之間的連接,研究人員得以精確描述模型的推理路徑。...