by Dr. Jackei Wong 2026-07-26 科技新聞 Gemini 逼近 10 億用戶:Google 用數據反駁「AI 侵蝕搜尋」的說法 Gemini 衝向 10 億用戶,Google 給出一個關鍵反命題 Gemini 月活用戶正在逼近 10 億,...
by Dr. Jackei Wong 2026-06-29 科技新聞 「MIT數學實錘、ChatGPT誘發AI精神病、14人死亡」是真的嗎?一次看懂傳言、風險與自保方法 「MIT數學實錘」這種說法,先從可驗證的地方開始 近期網路出現一種高度聳動的敘事:MIT 用數學證明 Chat...
by Dr. Jackei Wong 2026-06-28 科技新聞 跟 ChatGPT 愈聊愈笨?MIT 科學家罕見提前公開研究:真正風險可能不在「變笨」 最近「跟 ChatGPT 愈聊愈笨」的說法再度發酵,原因是一份由 MIT 研究團隊提前公開(尚未完成同儕審查)...
by Dr. Jackei Wong 2026-06-25 AI學堂-Youtube OpenAI Codex 開通教學:電話驗證卡關點解決?香港用家實測分享 不少香港用家想試 OpenAI Codex Desktop App,卻卡在電話驗證碼步驟。本文簡介影片中的 Hero SMS 實測流程,以及 Codex 新手使用前要留意的幾個重點。
by Dr. Jackei Wong 2026-06-24 科技新聞 OpenAI一年燒掉340億美元:營收暴增三倍,仍補不回的錢坑在哪? OpenAI從未公開的審計財報外流,數字比外界想像更刺眼。2025年總支出達340億美元,營收只有約130億美...
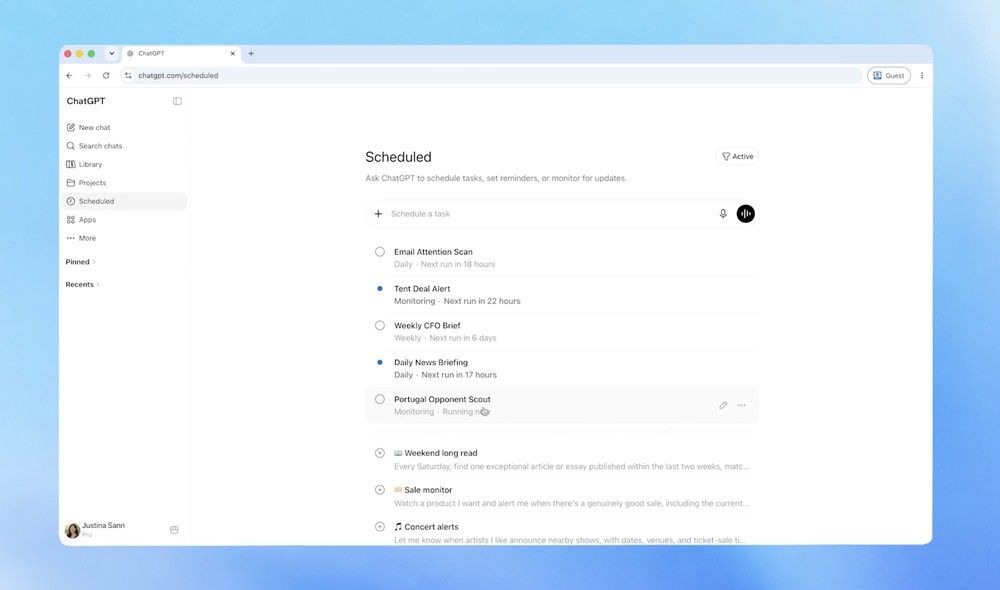
by Dr. Jackei Wong 2026-06-22 科技新聞 ChatGPT 排程任務正式登場:可定時監控網頁、APP,自動推送你關心的內容 ChatGPT 終於懂得「主動出擊」 ChatGPT 一直以來都是被動的——你問它才答,你不開對話它就什麼都不...
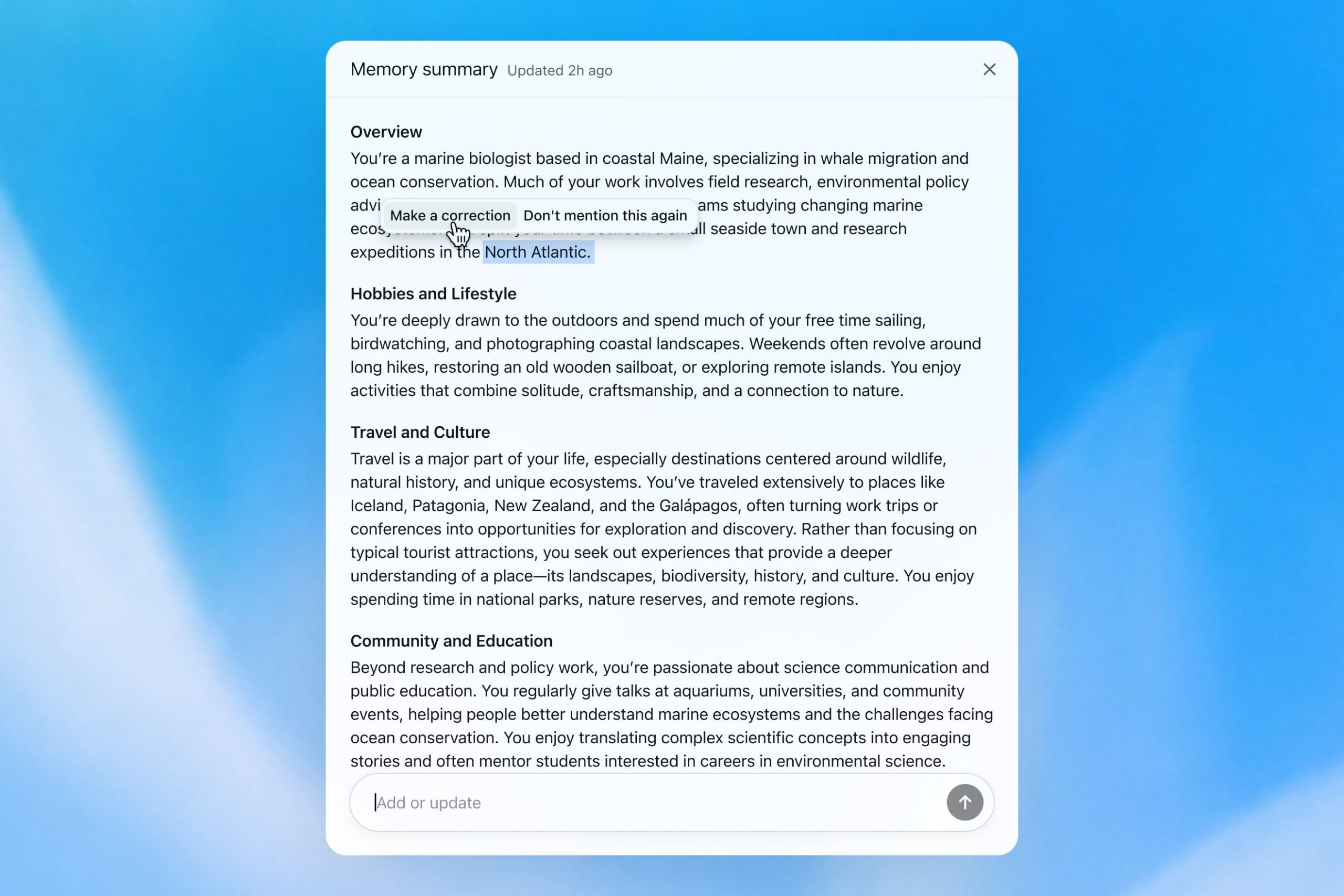
by Dr. Jackei Wong 2026-06-08 科技新聞 ChatGPT 記憶再進化:Dreaming V3 如何自動幫你整理偏好? OpenAI 最近推出了 ChatGPT 記憶功能的最新版本——Dreaming V3。這不是一次小修小補,而...
by Dr. Jackei Wong 2026-05-29 科技新聞 不只是換聊天機器人:從 ChatGPT 轉向 Claude 的遷移清單、風險控管與實戰玩法 當團隊決定「從 ChatGPT 轉向 Claude」,真正的工作往往不是註冊新帳號,而是把既有的知識、流程、權...
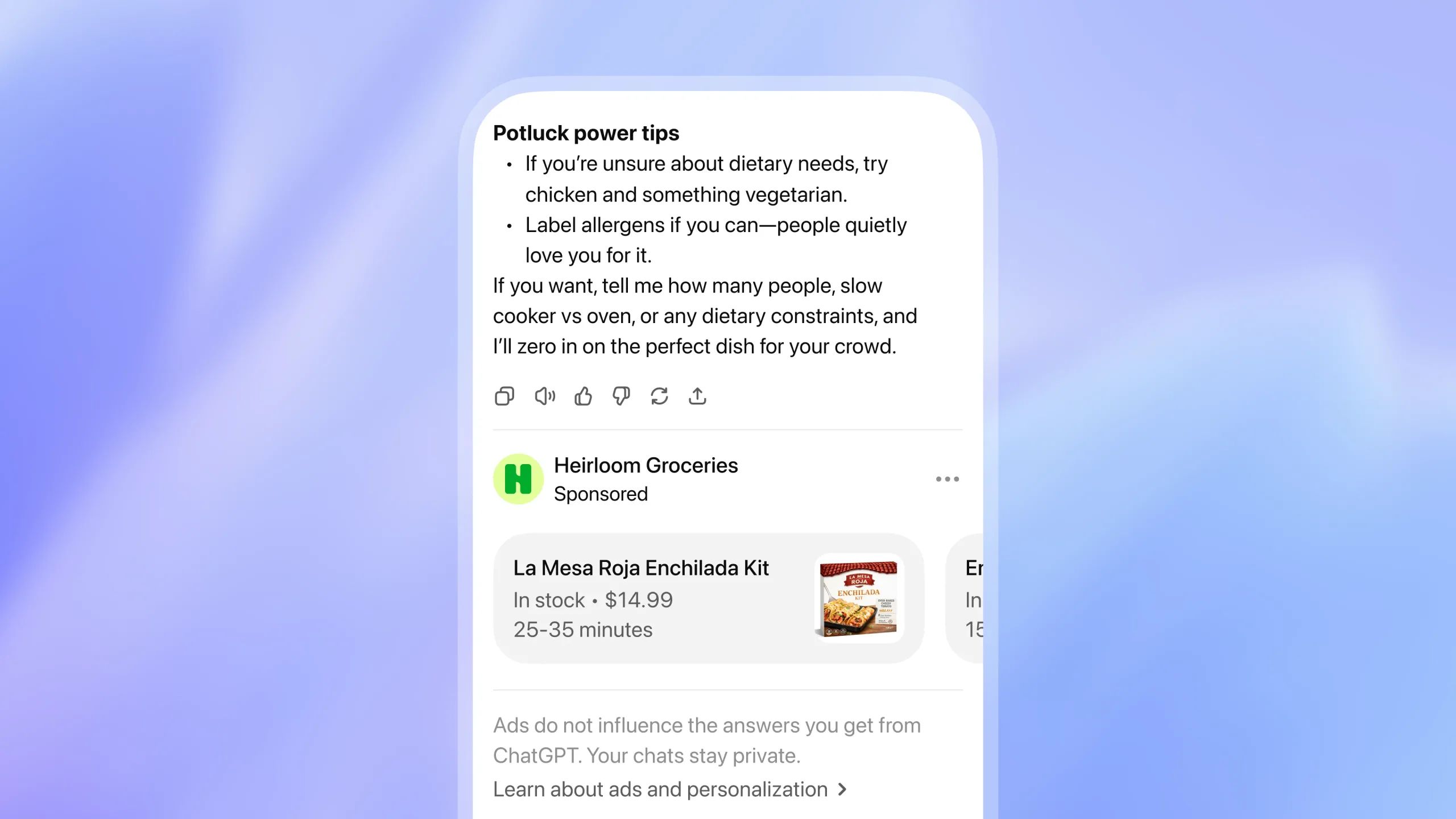
by Dr. Jackei Wong 2026-05-25 科技新聞 ChatGPT免費版變廣告平台:你的對話紀錄就是個人化廣告的燃料 OpenAI正在為ChatGPT免費版鋪設廣告系統,核心轉折在於:免費用戶的對話內容將被用於個人化廣告投放。這...
by Dr. Jackei Wong 2026-05-23 科技新聞 ChatGPT 不再讓你選模型:OpenAI 悄悄上線的自動切換機制,到底是方便還是麻煩? 如果你最近打開 ChatGPT,可能會發現一件奇怪的事:那個讓你手動切換 GPT-5.5 或 GPT-Inst...
by Dr. Jackei Wong 2026-05-21 科技新聞 ChatGPT 改進引用聊天歷史:細節提取變可靠,長期協作終於順暢 ChatGPT 近期針對引用聊天歷史功能推出了一項重要改進,核心在於更可靠地從過往對話中提取細節。對多數長期使...
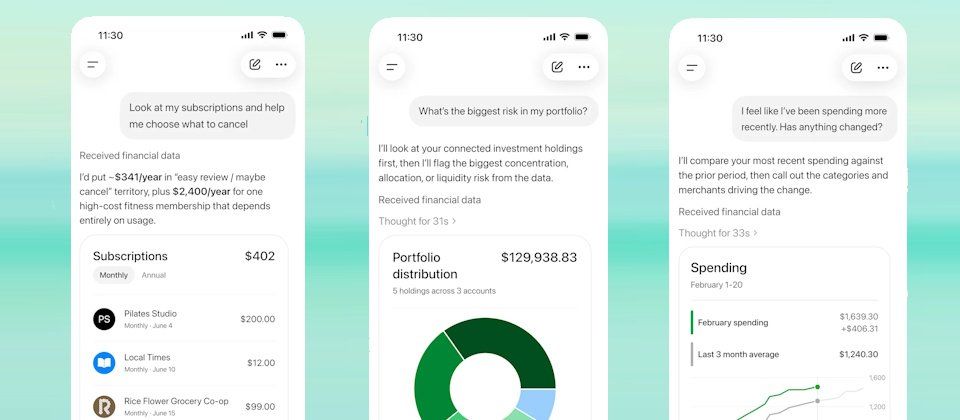
by Dr. Jackei Wong 2026-05-20 科技新聞 ChatGPT 新增個人理財功能預覽:連接銀行帳戶,用對話就能管好錢 OpenAI 最近在美國 Pro 用戶中推出了 ChatGPT 個人理財功能的預覽版。簡單來說,你可以直接把銀...