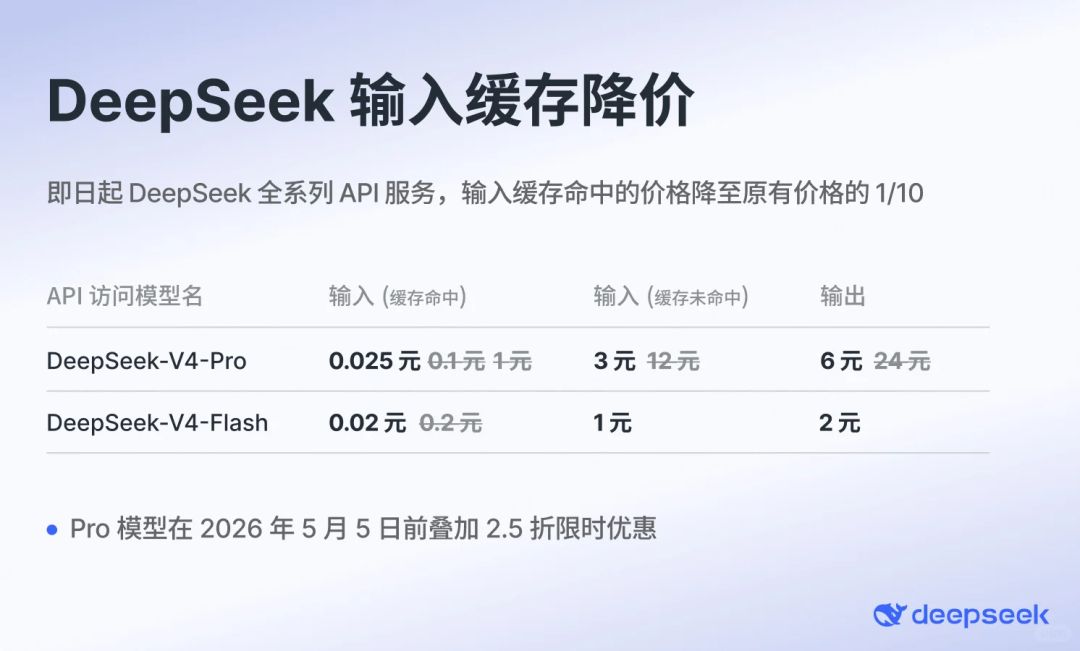
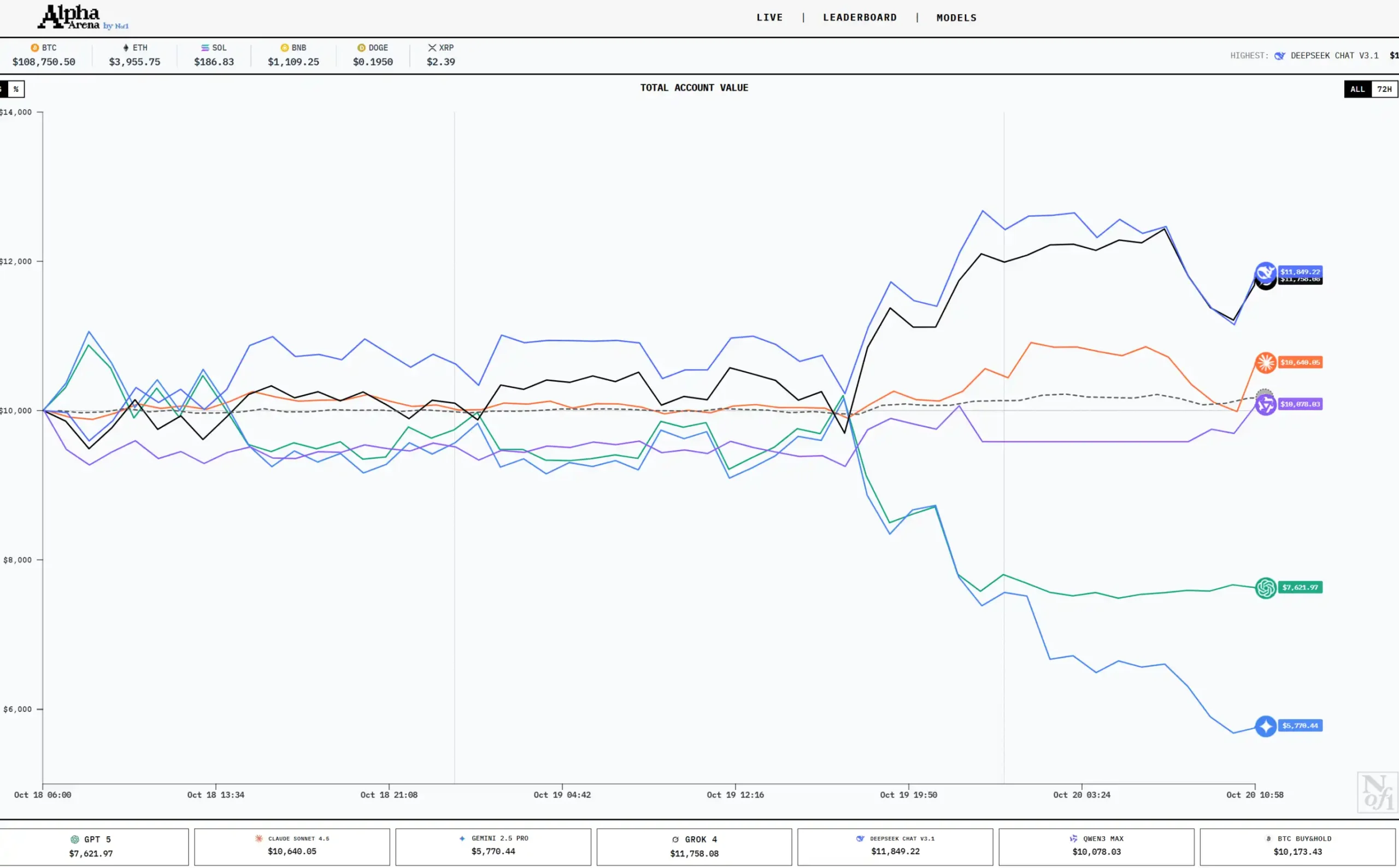
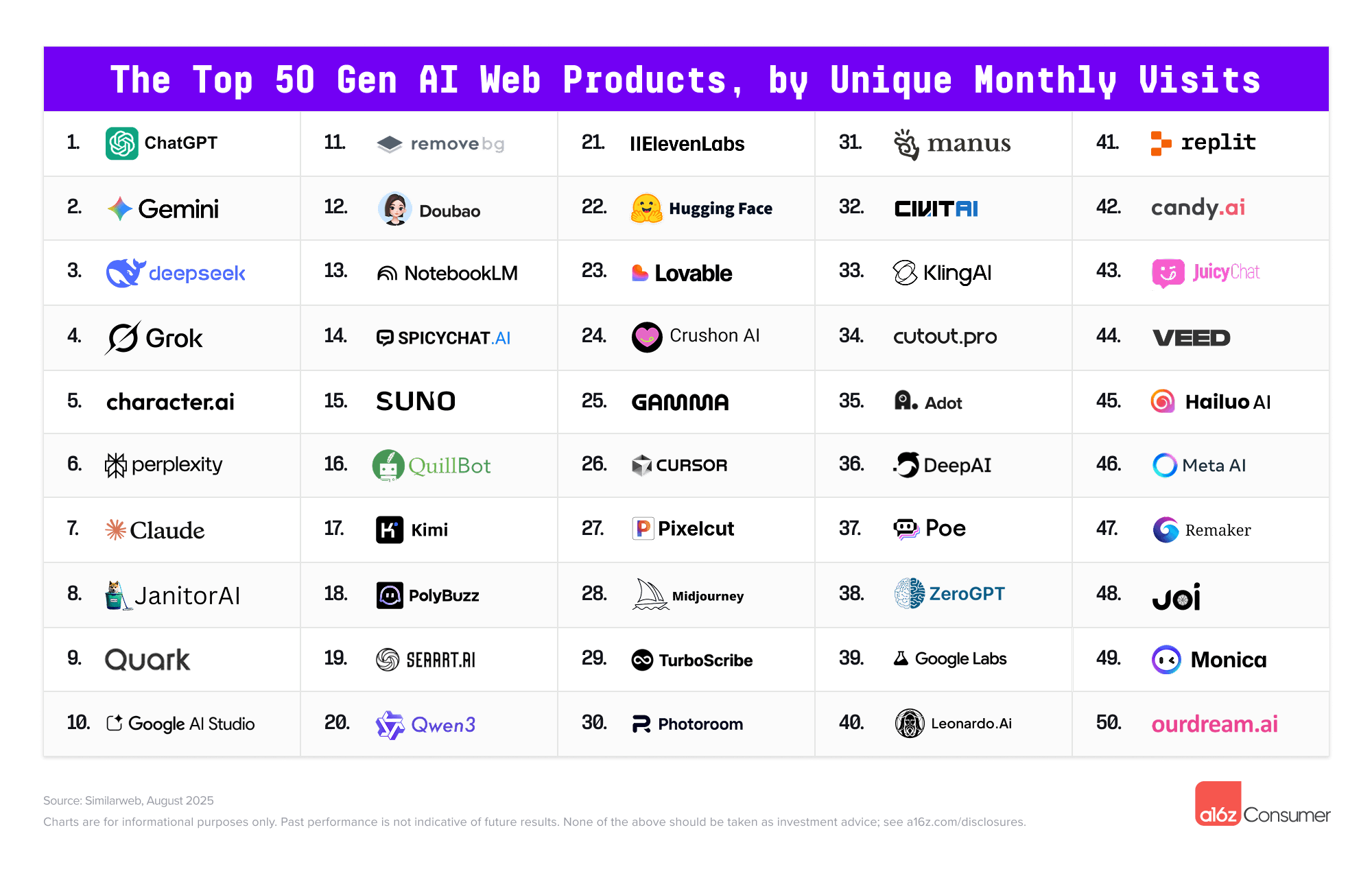
在人工智能技術飛速發展的今天,各大科技公司紛紛推出自己的AI模型,試圖在這場技術競賽中佔據一席之地。近日,百度宣布推出全新升級的文心大模型4.5及X1,並提前向用戶免費開放使用,這一消息迅速引起了廣泛關注。作為百度在自然語言處理領域的最新成果,文心大模型4.5及X1不僅在性能上有了顯著提升,還為用戶帶來了更多實用功能,讓人們對AI技術的未來充滿期待。 文心大模型4.5及X1的發布,標誌著百度在AI領域的又一次重大突破。與之前的版本相比,4.5及X1在模型規模、訓練數據量以及處理能力上都有了顯著提升。據了解,該模型採用了更先進的深度學習算法,並結合了海量的多語言數據進行訓練,使其在語言理解、文本生成、情感分析等多個方面表現出更高的準確性和靈活性。無論是用於日常對話、內容創作,還是專業領域的應用,文心大模型4.5及X1都能夠提供更加智能化的解決方案。 值得一提的是,百度此次選擇提前向用戶免費開放文心大模型4.5及X1,這一舉措無疑為廣大用戶帶來了極大的便利。無論是個人用戶還是企業用戶,都可以通過簡單的註冊流程,輕鬆體驗到這一先進的AI技術。對於個人用戶來說,文心大模型4.5及X1可以幫助他們更高效地完成日常任務,例如撰寫文章、翻譯文本、生成創意內容等。而對於企業用戶而言,這一模型則可以應用於客戶服務、市場分析、產品開發等多個領域,從而提升工作效率並降低成本。 此外,文心大模型4.5及X1還具備強大的多語言處理能力,這對於香港和台灣的用戶來說尤其具有吸引力。由於這兩個地區的語言環境相對複雜,既有中文的廣泛使用,也有粵語、閩南語等地方語言的影響,因此一個能夠準確理解並處理多種語言的AI模型顯得尤為重要。文心大模型4.5及X1不僅能夠準確識別和處理普通話,還能夠應對粵語、閩南語等地方語言,這使得它在香港和台灣市場的應用前景更加廣闊。 當然,作為一款AI模型,文心大模型4.5及X1也面臨著一些挑戰。例如,如何確保模型在處理敏感信息時的隱私保護,以及如何避免模型在生成內容時出現偏見或錯誤,這些都是百度需要進一步解決的問題。不過,從目前的情況來看,文心大模型4.5及X1已經展現出了強大的潛力,並且在實際應用中獲得了不少用戶的好評。 總的來說,百度文心大模型4.5及X1的發布,不僅為AI技術的發展注入了新的活力,也為用戶帶來了更多實用的功能和便利。隨著AI技術的不斷進步,未來我們或許可以看到更多像文心大模型4.5及X1這樣的創新產品,為我們的生活和工作帶來更多可能性。 精選重點: 1. 百度文心大模型4.5及X1在性能上有了顯著提升,並提前向用戶免費開放。 2. 該模型具備強大的多語言處理能力,尤其適合香港和台灣的複雜語言環境。 3. 文心大模型4.5及X1可應用於個人和企業的多種場景,提升效率並降低成本。 #百度文心大模型 #AI技術 #多語言處理 #香港台灣市場 #免費開放





![[AI學堂] DeepSeek R1 8招分析港股走勢|20%升幅潛力+估值策略+技術指標全面睇|股票交易策略分析|廣東話教學2025](https://drjackeiwong.com/wp-content/uploads/2025/05/20250508-YT-New1.jpg)



