by Dr. Jackei Wong 2026-07-14 科技新聞 GPT-5.6 Prompt Best Practices 實用資料包:OpenAI 官方 5 大原則+中英 Prompt 模板 整理 OpenAI 官方 GPT-5.6 Prompt Best Practices,涵蓋精簡 Prompt、結果導向寫法、行動權限設定、語氣控制、Pro mode 及 Programmatic Tool Calling,並附中英對照 Prompt 模板。
by Dr. Jackei Wong 2026-06-25 科技新聞 字節跳動變身 Microsoft 大客戶:在美國禁令下,照樣用得到 OpenAI 模型的真正原因 最近一單比較少人深入講、但其實非常值得留意嘅事:TikTok 母公司字節跳動,已經悄悄成為 Microsoft...
by Dr. Jackei Wong 2026-06-24 科技新聞 OpenAI一年燒掉340億美元:營收暴增三倍,仍補不回的錢坑在哪? OpenAI從未公開的審計財報外流,數字比外界想像更刺眼。2025年總支出達340億美元,營收只有約130億美...
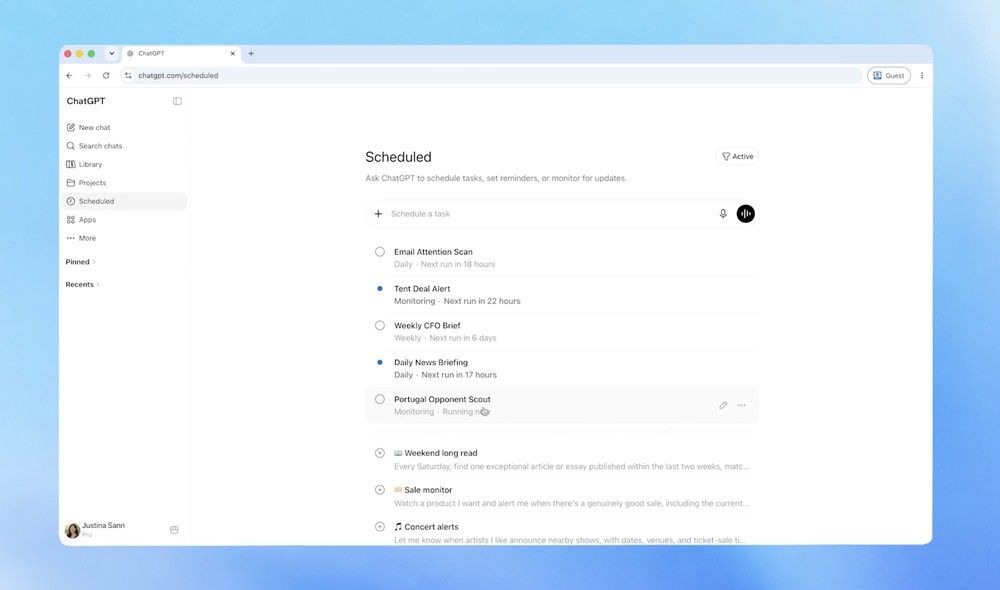
by Dr. Jackei Wong 2026-06-22 科技新聞 ChatGPT 排程任務正式登場:可定時監控網頁、APP,自動推送你關心的內容 ChatGPT 終於懂得「主動出擊」 ChatGPT 一直以來都是被動的——你問它才答,你不開對話它就什麼都不...
by Dr. Jackei Wong 2026-06-18 科技新聞 AI 真的能越用越強?史丹福博士生提出「持續自我提升」架構,為何連 OpenAI、Meta 都關注 AI 開始學會「自己變強」了嗎? 近期一項來自史丹福大學博士生的研究展示,引起 AI 圈高度關注。原因不只是技...
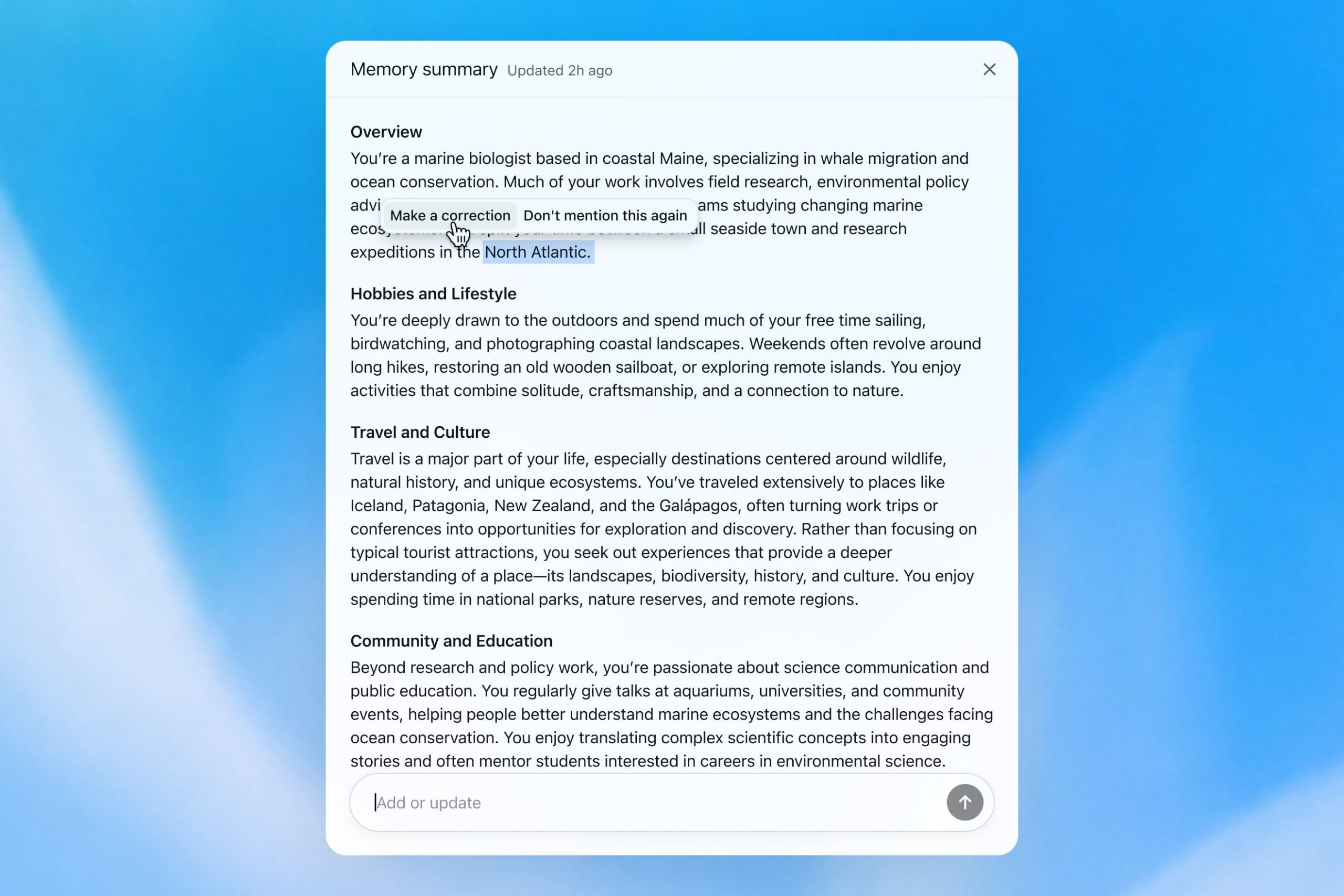
by Dr. Jackei Wong 2026-06-08 科技新聞 ChatGPT 記憶再進化:Dreaming V3 如何自動幫你整理偏好? OpenAI 最近推出了 ChatGPT 記憶功能的最新版本——Dreaming V3。這不是一次小修小補,而...
by Dr. Jackei Wong 2026-06-03 科技新聞 OpenAI Codex 不再只寫 code:辦公室外掛、Sites 與 Annotations 實戰解讀 OpenAI 近日為 Codex 加入三項重要更新:辦公室工作專用外掛、Sites 功能、以及支援所有文件的...
by Dr. Jackei Wong 2026-06-01 科技新聞 Windows 版 Codex 終於開放 Computer Use 功能:值得立即試的 3 個升級亮點 如果一直有在關注 AI 代理工具的發展,應該會記得 OpenAI 的 Codex 在去年展示過一項讓人印象深刻...
by Dr. Jackei Wong 2026-05-30 科技新聞 OpenAI 奧特曼認錯:AI 不會消滅白領工作,我當初的預測錯在哪裡 OpenAI 奧特曼認錯:AI 不會消滅白領工作,我當初的預測錯在哪裡 OpenAI 執行長 Sam Altm...
by Dr. Jackei Wong 2026-05-26 科技新聞 OpenClaw每月燒1018萬港元全是AI模型錢 OpenAI為何甘願全額買單 OpenClaw開發團隊每月營運成本高達1018萬港元,而且這筆開銷幾乎全部來自AI模型的API費用。當外界還...
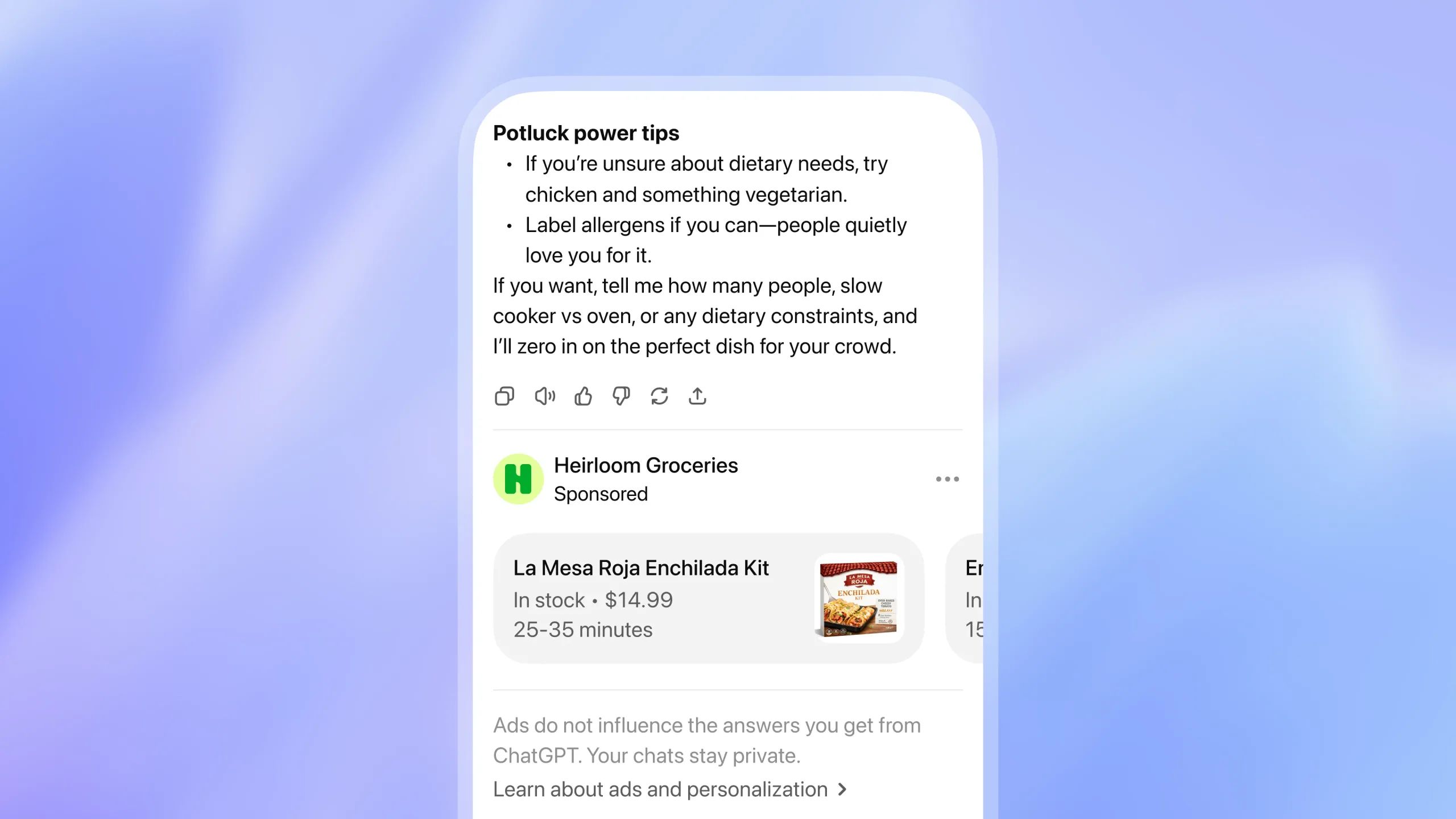
by Dr. Jackei Wong 2026-05-25 科技新聞 ChatGPT免費版變廣告平台:你的對話紀錄就是個人化廣告的燃料 OpenAI正在為ChatGPT免費版鋪設廣告系統,核心轉折在於:免費用戶的對話內容將被用於個人化廣告投放。這...
by Dr. Jackei Wong 2026-05-24 科技新聞 OpenAI 稱八成程式碼 AI 生成,專家為何說數字不可信? OpenAI 近期宣稱,其內部與平台上已有高達八成的程式碼由 AI 生成。這個數字一出,立刻成為科技圈熱議焦點...