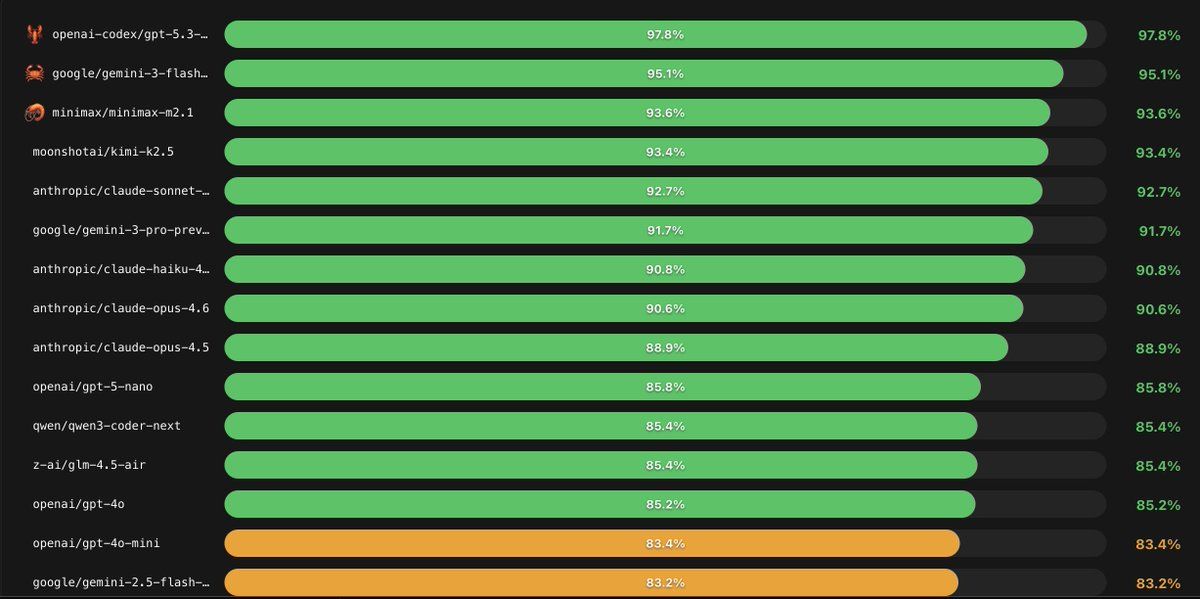
OpenClaw 釋出官方 Agent 成功率(success rate) 數據後,很多人第一個問題都是:「到底哪個模型最強?」但如果只把榜單當成冠軍賽排名,很容易選錯工具、甚至把 PoC 做到一半才發現成本、穩定性或安全性不合用。
這篇文章會用「如何讀懂成功率」為主線,帶你看 OpenClaw 類評測在說什麼、沒說什麼,以及不同使用情境該怎麼把數據轉成可落地的選型決策。
成功率到底測到什麼?它其實在測「把事情做完」的能力
一般聊天模型評估常看回答品質或知識正確性;但 Agent 評估(像 OpenClaw)更接近真實工作:
- 需要多步推理:拆解任務、規劃步驟、調整策略
- 需要工具使用:呼叫搜尋、瀏覽器、API、程式執行、檔案處理等
- 需要狀態管理:記住已做過什麼、避免重複、處理中斷與回復
因此「成功率」的直覺意義是:在固定環境與規則下,模型作為 Agent 能否把任務完整交付。對想做自動化工作流、客服助手、資料整理、內部營運工具的人來說,這比單輪問答更接近實戰。
為什麼榜單一公布,大家仍會得出相反結論?關鍵在你怎麼解讀「最強」
OpenClaw 的成功率數據通常會讓人看到一個現象:頂尖模型的確領先,但差距不一定能直接換算成你的業務效益。原因在於:
- 任務類型權重:如果評測任務偏向網頁操作、資訊擷取、表單填寫,對你做「內部文件摘要」的參考價值有限
- 工具鏈設定:同一個模型,在不同的 tool calling 格式、重試策略、檔案系統限制下,成功率可能大幅波動
- 失敗型態差異:有的模型「敢做」但容易誤操作;有的模型「保守」導致卡關。兩者成功率相近,但風險完全不同
所以與其問「最強模型是哪個」,更實用的問題是:
- 它在我需要的任務上,成功率高嗎?
- 失敗時是可控、可回復,還是會把事情做壞?
- 成本與延遲,能不能支持我的流量與 SLA?
你可以從官方成功率推回三個「實戰訊號」
以下是成功率榜單最值得拿來做決策的三種訊號(比單看名次更有用):
1) 穩定跨任務的模型:適合做「通用型 Agent」底座
如果某模型在多種任務都表現穩定,代表它的規劃與工具使用能力較均衡。這類模型通常適合作為:
- 企業內部的通用助理(報表整理、資料查找、流程代辦)
- 需要跨系統操作的工作流(CRM、工單、知識庫、郵件)
- 你還不確定需求會怎麼變動的產品早期
但代價常見是:單次成本較高、或是需要更嚴格的權限與審核機制。
2) 某類任務特別強的模型:適合做「分工路由」
有些模型可能在「瀏覽器操作」或「程式執行」特別突出,但在其他任務普通。這很適合做:
- Router 架構:先分類任務,再把適合的工作交給擅長的模型
- 混合成本策略:簡單任務用便宜模型,關鍵步驟或高風險步驟用強模型
這種作法往往比「全程用最強」更省錢,也更容易把成功率拉到可用門檻。
3) 成功率接近但成本差很大:要看「每次成功的成本」
Agent 場景不能只看成功率,還要把:
- 重試次數
- 平均步數
- token 用量
- 延遲
一起納入。實務上常用的衡量方式是把榜單轉成:Cost per Successful Task(每次成功任務成本)。有些模型成功率略低,但只要搭配良好的重試與護欄,整體 ROI 反而更好。
對不同讀者/產業,這份數據各自代表什麼?
產品與工程團隊:把榜單當成「起跑線」,不是答案
你可以用 OpenClaw 的官方成功率做兩件事:
- 縮小候選清單:先挑 2–4 個在你任務類型接近的模型
- 快速建立 PoC 指標:把「成功 / 失敗」定義寫清楚(例如完成表單提交才算成功)
接著在你自己的環境做 A/B:同樣的工具、同樣的限制、同樣的資料權限,才會得出可用結論。
行銷與內容團隊:成功率高不代表內容更好,但代表「可交付」更穩
內容工作常見的 Agent 任務包括:
- 蒐集資料與引用來源
- 產出大綱、比對競品、整理 FAQ
- 在 CMS 建立草稿、補齊 meta、插入內部連結
成功率提升意味著「流程跑得完」,但你仍需要把關:來源可信度、語氣一致性、品牌合規。建議把 Agent 設計成「先整理再由人核對」的流程,而不是全自動發布。
企業決策者:成功率榜單無法替你回答「風險承擔」
Agent 會動用工具與權限,成功率越高,往往代表它越敢執行動作。你要同步評估:
- 權限控管(最小權限、分級授權)
- 可追溯性(操作紀錄、版本、輸出與依據)
- 防呆機制(高風險操作需二次確認、人審)
否則「成功完成任務」可能也包含了「以錯誤方式完成」。
可能的限制與爭議:為什麼你不該把成功率當作唯一 KPI
即使是官方數據,也常見幾個可預期的爭點:
- 任務集偏差:任務設計偏向某類工具或互動方式,會放大特定模型或特定提示策略的優勢
- 環境可重現性:瀏覽器版面、網站變動、速率限制,都可能影響結果
- 安全與合規未必等權重:成功率指向「完成」,但不一定衡量「是否合規完成」
- 提示工程與框架依賴:同一模型在不同 Agent 框架(規劃器、記憶、重試策略)下表現可能差很多
因此最佳做法是:把 OpenClaw 這類榜單當作「第三方參考」,再用自己的任務、資料與權限模型做一次「內部基準」。
讀完榜單後的選型建議:用一張清單把數據落地
如果你要把「最強模型」變成「最適合我的模型」,建議依序回答:
- 我的任務是「找資料」多,還是「動作執行」多?
- 失敗的代價是什麼(多花時間 vs 造成損失)?
- 我能接受的延遲與成本上限?
- 需要哪些護欄(敏感資料遮罩、白名單網站、操作前確認)?
- 是否能做路由與分工(不用全程押同一個模型)?
把這些問題對上 OpenClaw 的成功率分佈與你的 PoC 結果,你會更接近真正的「最強」:在你的場景裡最穩、最省、最可控的那個組合。
我的整體觀察
OpenClaw 官方成功率數據的價值,不在於替所有人宣布冠軍,而在於它把「Agent 能不能把事情做完」這件事量化了。下一階段的差異化,會更集中在:可控的工具使用、可靠的失敗回復、以及把成本壓到可規模化。對多數團隊來說,「最強模型」往往不是單一模型,而是「強模型 + 護欄 + 路由 + 監控」的系統答案。
追蹤以下平台,獲得最新AI資訊:
Facebook: https://www.facebook.com/drjackeiwong/
Instagram: https://www.instagram.com/drjackeiwong/
Threads: https://www.threads.net/@drjackeiwong/
YouTube: https://www.youtube.com/@drjackeiwong/
Website: https://drjackeiwong.com/