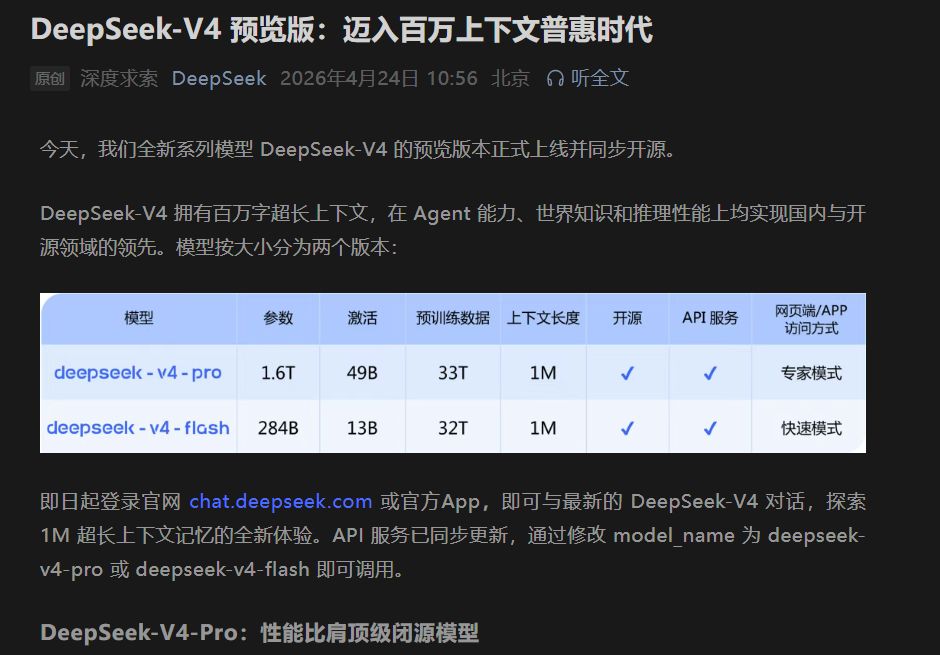
DeepSeek-V4 終於發布,市場上最醒目的訊號不是「又多一個能聊的模型」,而是開源陣營再一次把能力拉到接近頂級閉源模型的高度。你最該先關注的,是它是否真的能在推理、寫程式與長任務穩定性上站得住腳;而我的判斷是:DeepSeek-V4 的價值不在於幫你省下一點 API 費用,而在於它把「可控、可自架、可被你整合進流程」這件事,重新拉回到頂級能力的同一張桌上。
有些人把這種更新理解成「開源追上閉源」,我更在意的是另一件事:閉源模型正在把競爭主場,從「答得多準」推進到「能不能替你把事情做完」。像 GPT-5.5 被定位成更強的代理式模型,強調可以在較少人工干預下規劃步驟、使用工具、檢查結果並推進多步驟任務。Codex 甚至開始把「電腦操作、內建瀏覽器、記憶與排程」打包成工作夥伴,能在 Mac 上看畫面、點擊、輸入並在背景並行跑任務。
所以,DeepSeek-V4 這次的問題不是「像不像某個閉源模型」,而是:它能不能成為你自己的代理與工作流程底座。
這次更新最值得盯緊的 4 個點(比規格表更重要)
先說清楚:在新模型剛發布的前期,比起背規格與榜單,我會建議你用「能不能落地」來驗證。下面 4 點,是我認為最值得優先測的升級方向,也是開源模型能否真正比肩閉源的分水嶺。
1) 推理的「可預期性」:不是聰明一次,是穩定聰明
如果 DeepSeek-V4 只是偶爾答得很神,但一進到多步驟任務就飄,那它仍然只是展示品。
你要測的是:同一題、同一份資料、同一套指令下,它能否維持一致的解題路徑與結論品質。開源要贏閉源,靠的不是靈感,是可重現。
2) 寫程式與除錯:看它會不會「自我驗收」
很多模型會寫,但不會收尾:沒跑測試、沒檢查邊界、沒把錯誤訊息吃回去修。
你要觀察的是:它能否把「產出程式碼」往前推到「跑起來、能驗證、能修正」。這也是為什麼我會拿 Codex 的電腦操作示範當對照:它被期待能自行測試、找 bug、修正再重跑。DeepSeek-V4 若要被認真當成工作底座,至少要在同一個方向上站得住。
3) 長文與長任務:能不能在中途不失憶、不換人格
內容工作者最常遇到的痛點不是「它不會寫」,而是「寫到一半就忘了前面立場」。
你要測的是:一篇 2,000–3,000 字的觀點文,從立論、例子、反駁、到收束,能不能維持一致的價值判斷與語氣。如果它做得到,開源模型才真正具備進入內容產線的資格。
4) 成本與部署彈性:能不能讓你把能力留在自己手上
開源的核心利益不是便宜,而是主控權:你可以決定資料怎麼留、模型怎麼包、流程怎麼做版本管理。
一句話:閉源賣的是「即用」,開源賣的是「可控」。能控到哪裡,才是你拿到多少價值。
「比肩閉源」的真正門檻:代理化時代,模型只是零件
現在很多討論把焦點放在分數與對打,但閉源陣營的攻勢已經往前一步:把模型變成會跑流程的代理。
GPT-5.5 被強調能更理解意圖、規劃步驟、用工具、檢查結果並推進複雜工作。Codex 更進一步把電腦操作、內建瀏覽器、外掛整合、記憶與排程做成「可常駐」的工作夥伴。
這裡有個很殘酷的現實:
- 你以為你在選模型,其實你在選工作作業系統。
- 模型能力差距縮小後,差的會是「你能不能把它變成你的流程」。
DeepSeek-V4 若要讓「開源比肩」變成真事,它接下來的關鍵不是再多幾個漂亮榜單,而是:社群與工具鏈能否把它推進代理化(工具使用、任務拆解、驗收回饋、記憶與長期任務)這條路。
兩個你很可能真的會用到的情境
情境一:內容團隊把「觀點庫」留在自己手上,而不是每次都重寫人格
很多人用 AI 寫文,最後會變成大家長得一樣。問題通常不在模型,而在你沒有把「你是誰」餵給系統:沒有靈感庫、沒有觀點庫、沒有你的核心信念,模型當然只能寫出最大公約數(這個提醒我很認同)。
DeepSeek-V4 這類開源模型的優勢在於:你可以把公司的風格手冊、過往爆文拆解、產品立場與常見反對意見整理成內部知識,讓它變成「內容副駕」而不是「代筆」。
情境二:工程/產品小組需要可控的內部助理,願意用整合換主控權
當你做內部文件、規格書、客服回覆模板、或把一堆零散會議紀錄收斂成決策紀要時,閉源服務的便利很香,但很多團隊會卡在資料合規、權限、與長期成本。
DeepSeek-V4 若能在你自己的環境中被穩定呼叫、能配合你們的工具(Issue、文件、測試、佈署流程)形成「可重複」的任務腳本,它就不只是模型,而是你們的內部自動化骨幹。
值不值得立刻跟進?我的建議是「試,但別急著信仰」
我會把跟進分成兩個層級:
- 你該立刻試的原因:開源能把頂級能力拉近,就等於把議價權與選擇權拉回到你手上。越早測,你越早知道哪些工作能從閉源遷出,哪些仍必須留在閉源。
- 你不該立刻押注的原因:代理化工具鏈正在快速重塑使用體驗,閉源的優勢常常不是模型本體,而是整套「能做事」的介面、記憶、外掛與工作區。你要確認 DeepSeek-V4 在你手上的「可用性」,是否真的能抵過這些整合紅利。
最後留兩句我希望你記住:
- 當模型越來越像,差異會回到你到底有沒有自己的資料、觀點與流程。
- 開源的勝利不是跑分第一,而是你能把它裝進自己的工作裡,還能長期維護。
追蹤以下平台,獲得最新AI資訊:
Facebook: https://www.facebook.com/drjackeiwong/
Instagram: https://www.instagram.com/drjackeiwong/
Threads: https://www.threads.net/@drjackeiwong/
YouTube: https://www.youtube.com/@drjackeiwong/
Website: https://drjackeiwong.com/