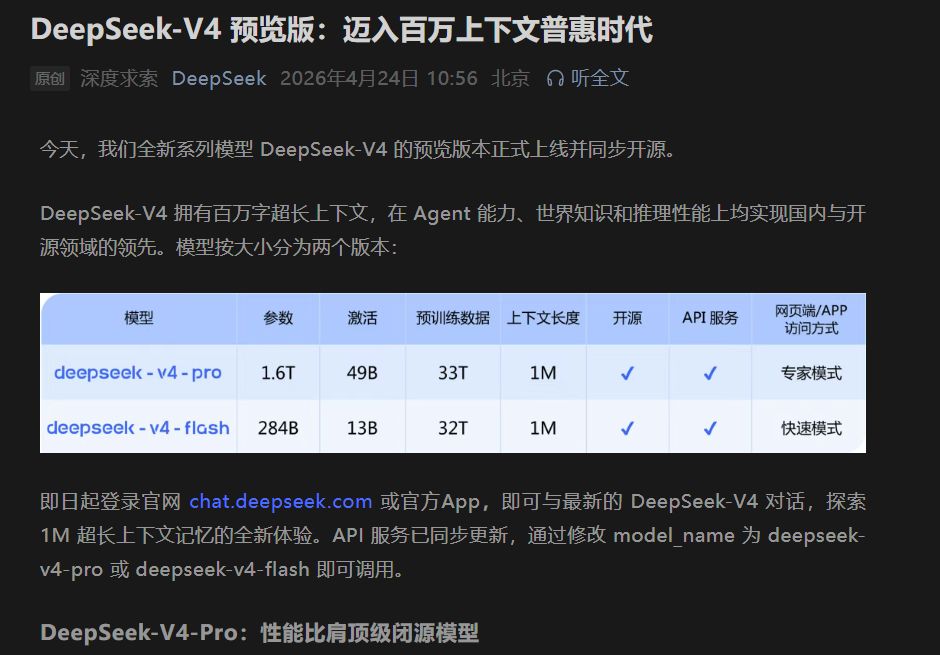
by Dr. Jackei Wong 2026-04-25 科技新聞 DeepSeek-V4 發布:開源再度逼近頂級閉源模型,重點其實是「你能不能把它變成自己的底層能力」 DeepSeek-V4 終於發布,市場上最醒目的訊號不是「又多一個能聊的模型」,而是開源陣營再一次把能力拉到接...