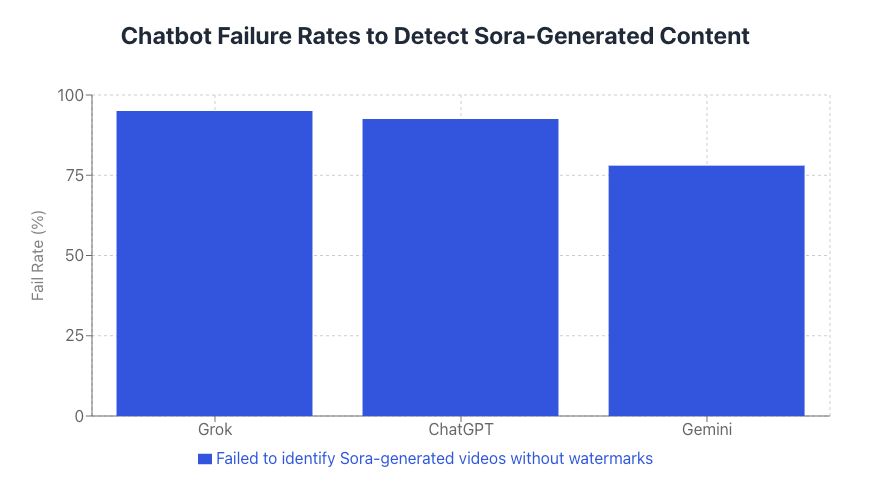
AI 聊天機器人辨識 AI 生成影片的能力,正在成為資訊安全與選舉公信力的關鍵議題。當深偽技術與文字轉影片模型愈來愈強大時,如果連 AI 聊天機器人本身都難以分辨 AI 生成影片與真實畫面,我們對「數位真相」的基本假設就必須全面重寫。
AI 聊天機器人為何難以辨識 AI 生成影片?
多數人直覺會以為:既然聊天機器人是 AI,理論上應該更懂得如何識破 AI 生成影片。事實剛好相反,現階段的主流程設計,主要是為了「理解與生成內容」,而不是為了「鑑定真偽」。
技術架構上的天生盲點
當前主流 AI 聊天機器人(包括 ChatGPT、Gemini、Grok 等)多半是:
- 以文字大型語言模型為核心
- 再疊加影像、影片理解能力,變成多模態模型
- 主要優化目標是「流暢回答」、「有用且安全的回覆」
這樣的架構帶來幾個天生盲點:
- 傾向「補完故事」而非「拒答」
模型被訓練成儘量幫你完成任務,而不是懷疑你的題目。當你問「這支影片是真的嗎?」時,它更像是在從語意與背景知識中推敲一個「看起來合理的回答」,而不是在做嚴謹的鑑識。 -
缺乏專用的鑑識模組
影像取樣分析、壓縮噪點檢測、像素層級不連續等「鑑識級」技術,往往存在於專門的深偽偵測模型中,而不是一般對話型 AI 的預設能力。 -
訓練資料與目標不一致
多數聊天機器人是用大量文字與圖片學習「描述世界」,而不是用經過標記的真偽影片數據庫去學「判斷真假」。在沒有大量標註「這是 AI 影片、那是實拍影片」的情況下,辨識能力自然有限。
水印與偵測工具的侷限
為了降低 AI 生成影片的風險,產業界常見作法是:
- 在 AI 生成影片上加入可見水印(logo 或文字)
- 或用類似數位浮水印、數位指紋的方式做不可見標記
然而,這套機制面臨幾個現實問題:
- 水印可以被裁切、模糊、覆蓋或利用專門工具移除
- 目前不同公司的水印與驗證工具並不互通
- 聊天機器人若沒有直接接入這些驗證系統,就無法可靠判斷
結果是:
就算影片原本有 AI 水印,只要經過一層簡單處理,再丟給 AI 聊天機器人,它很可能就會像一般使用者一樣,被「乾淨」的影像所欺騙。
深偽影片與選舉資訊戰的風險
當 AI 生成影片足以騙過 AI,本身就已經是治理上的重大警訊;若再放進選舉、國際衝突、公共衛生等高度敏感的情境,風險就被成倍放大。
從文字事實查核到影音事實查核
過去幾年,平台與事實查核機構已逐漸建立一套針對「文字貼文」與「新聞報導」的查核流程,例如:
- 針對關鍵字與典型假訊息框架,建立資料庫
- 建立即時查核機制與標記系統
- 推出讓使用者一鍵「事實查核」或觀看背景資訊的工具
但當戰場轉向短影音與直播:
- 深偽影片可以結合逼真的人聲、口型與表情
- 透過剪輯與配樂營造強烈情緒
- 在幾秒內就能塑造印象,遠勝一長段文字
此時若使用者習慣把影片丟給 AI 聊天機器人問一句「這是真的假的?」,而機器人又以高信心地回覆「看起來是真的」,那麼 AI 反而變成假訊息的「放大器」而不是「防火牆」。
不要把事實查核外包給聊天機器人
許多使用者對 AI 聊天機器人有一種誤解:
「既然它看起來博學多聞,那應該很適合幫我做事實查核。」
問題在於,當前聊天機器人的安全設計,多數是為了避免產生明顯有害內容,例如:
- 鼓勵暴力或自殘
- 直接提供犯罪技術
- 露骨仇恨言論
至於「錯把假訊息當成真實新聞」、「錯把 AI 生成影片當成實拍事件」,在模型訓練時往往沒有被當成同等級的高風險行為來處理。這種「安全優先順序錯位」導致:
- 模型願意長篇大論地解釋一支 AI 生成影片的「背景與細節」
- 卻很少一開始就明確告訴你:「我沒有可靠的影片鑑定能力」
換句話說,多數聊天機器人今天還不具備「把自己定位成不可靠的鑑定者」的謙卑設計。
使用者應該如何面對 AI 生成影片?
在技術與治理尚未成熟前,使用者本身必須建立一套「面對 AI 生成影片的自我防護機制」,而不是把風險完全交給平台或聊天機器人。
個人層面的「數位懷疑精神」
看到一支看似驚天動地的影片時,可以從幾個面向自我檢查:
- 情緒強度:是否刻意激起憤怒、恐懼或羞辱?情緒越強,越要小心。
- 來源不明:只有轉貼、沒有清楚原始媒體與時間地點標記?
- 技術細節:人物手指、反光、影子、邊緣是否略顯不自然?
- 交叉比對:到搜尋引擎或新聞網站查詢,是否有多家可信媒體同時報導?
而當你把影片丟給 AI 聊天機器人詢問時,應該把它的回答當成「輔助線索」,而不是「最終裁決」。任何帶有高度自信、卻沒有清楚說明判斷依據的答案,都應該視為可疑。
平台與產業需要承擔的責任
單靠個人警覺是不夠的,平台與開發者也有幾項責任難以迴避:
- 預設不把聊天機器人當成鑑定工具
在介面上清楚標示:對於圖片與影片,系統僅提供「理解與描述」,並非專業鑑定。 -
將驗證工具深度整合進多模態模型
不是事後再開一個獨立的「深偽檢測網站」,而是讓聊天機器人在看到影音檔時,先經過鑑識模型與水印驗證,再決定如何回答。 -
規範「過度自信」的語氣
若模型對真偽沒有高把握度,應優先使用「不確定」、「無法判斷」等表述,而不是用百分之百肯定的語氣回答。 -
針對選舉與公共議題設計特別防線
一旦問題牽涉候選人、政黨、戰爭、疫苗等敏感主題,模型應有更嚴格的回覆策略,例如強制附上多元觀點摘要與風險提示。
為何「AI 應該能看穿 AI」這個期待是危險的?
社會輿論中常見一種天真的假設:
「既然假影片是 AI 做出來的,那就再用更強的 AI 來抓就好了。」
這種「用 AI 解決一切 AI 問題」的直覺,忽略了幾個關鍵事實:
- 生成與偵測是一場軍備競賽
生成模型每進步一代,偵測模型就被迫重新學習。落差期間,就是假訊息橫行的空窗期。 -
攻擊者只要成功一次,防守方得永遠成功
一支在關鍵時刻爆紅的假影片,就足以影響選情或社會情緒;而偵測系統就算有 90% 的準確率,仍無法避免那「致命的 10%」。 -
技術無法處理「人」的部分
就算將來 AI 偵測準確率更高,人們仍可能因為立場偏好而只相信符合自己觀點的結果。科技解決不了「相信什麼」的心理與政治問題。
因此,「相信 AI 一定比人更懂得看穿 AI」本身,就是一種新的資訊風險。
結語:在真假難辨的時代學會慢下來
AI 生成影片與 AI 聊天機器人的交會,正在改寫我們判斷真相的方式。當前的現實是:多數 AI 聊天機器人尚不足以可靠辨識 AI 生成影片,甚至在被刻意設計的情境中,會比一般人更容易被騙,卻仍以高度自信的語氣回答問題。
在技術與制度尚未跟上的這段時間,我們能做的包括:
- 把聊天機器人當作「說明工具」,而不是「驗證工具」
- 練習在情緒最激動時,刻意按下暫停鍵,多花幾分鐘交叉比對
- 要求平台與開發者在介面與設計上,誠實揭露系統的侷限
真相從來不是自動配送的服務,而是一種需要集體維護的公共基礎建設。在深偽與資訊戰成為日常的年代,最重要的行動,也許就是學會對每一支「剛好打中你情緒」的影片,先多問自己一次:「如果這是 AI 做的呢?」
#AI聊天機器人 #AI生成影片 #深偽影片 #資訊戰 #數位識讀
追蹤以下平台,獲得最新AI資訊:
Facebook: https://www.facebook.com/drjackeiwong/
Instagram: https://www.instagram.com/drjackeiwong/
Threads: https://www.threads.net/@drjackeiwong/
YouTube: https://www.youtube.com/@drjackeiwong/
Website: https://drjackeiwong.com/