by Dr. Jackei Wong 2026-07-03 科技新聞 Anthropic 出手堵後門:螞蟻、字節跳動借海外子公司偷用 Claude,這場圍堵怎樣升級? Anthropic 出手堵後門:螞蟻、字節跳動借海外子公司偷用 Claude,這場圍堵怎樣升級? Anthro...
by Dr. Jackei Wong 2026-06-15 科技新聞 Claude Cowork、Chat、Code 怎麼選?三種生成式 AI 工作流模式全攻略,讓知識工作效率翻倍 生成式 AI 早就不只是「問答機器」,真正拉開效率差距的,是你能不能把它嵌進日常流程:從需求釐清、資料整理、產...
by Dr. Jackei Wong 2026-05-29 科技新聞 不只是換聊天機器人:從 ChatGPT 轉向 Claude 的遷移清單、風險控管與實戰玩法 當團隊決定「從 ChatGPT 轉向 Claude」,真正的工作往往不是註冊新帳號,而是把既有的知識、流程、權...
by Dr. Jackei Wong 2026-05-19 科技新聞 Anthropic 用自然語言解鎖 Claude 黑箱:你該知道的不是技術,而是這代表什麼 Anthropic 最近做了一件事,值得每一個靠 AI 做事的人留意:他們開發出一種自然語言自編碼器,能夠把...
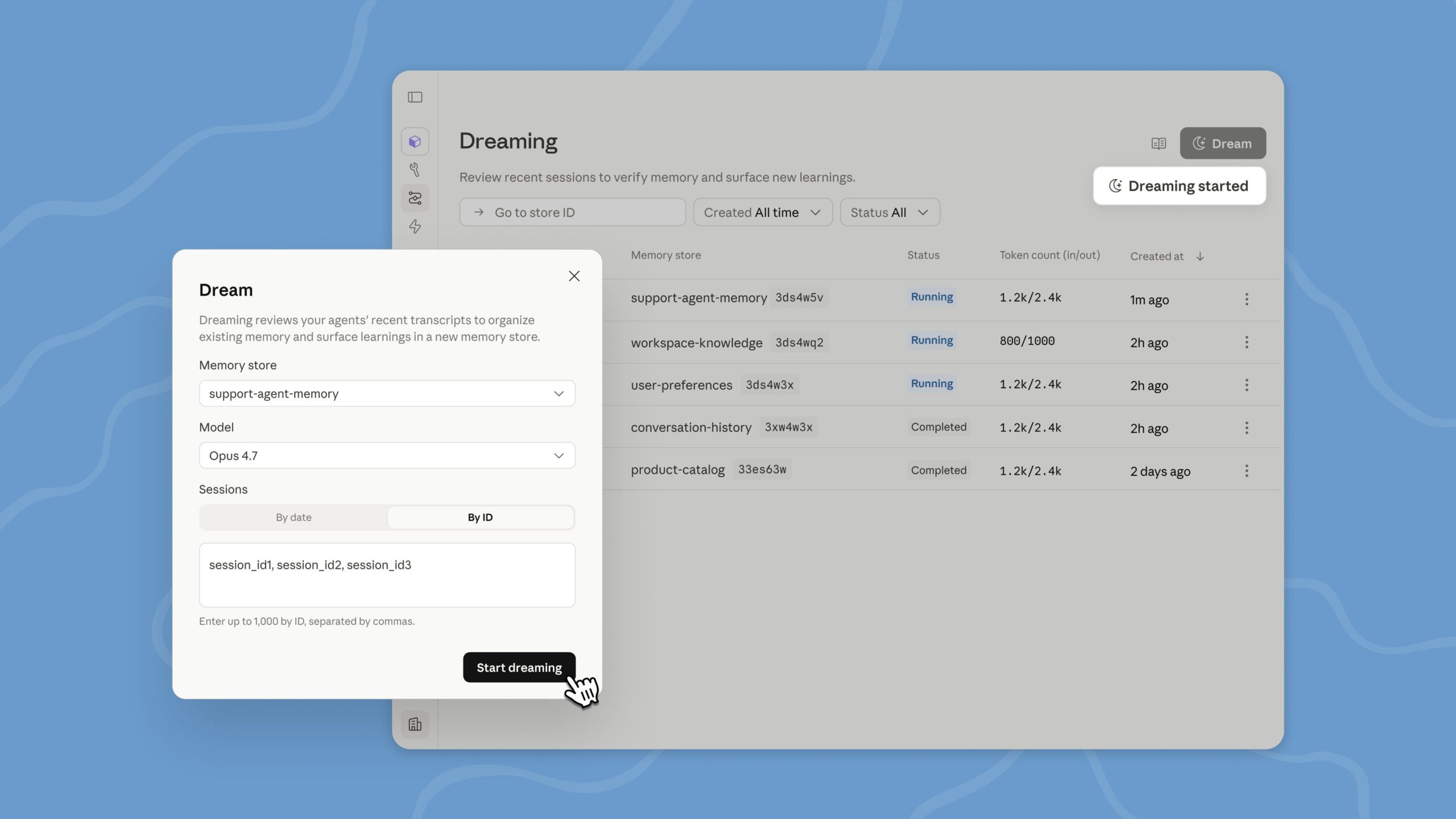
by Dr. Jackei Wong 2026-05-13 科技新聞 Anthropic 教會 Claude「做夢」:AI 自動整理記憶,反而減少出錯 Anthropic 最近做了一件聽起來很科幻、但實際上非常務實的事:他們教 Claude 學會「做夢」。 不是...
by Dr. Jackei Wong 2026-04-29 科技新聞 Claude for Creative Work 真正新在「跨工具協作」:把 Adobe、Blender、Ableton 串成一條創作指令鏈 Anthropic 推出 Claude for Creative Work,把 Claude 從「聊天式靈感來...
by Dr. Jackei Wong 2026-04-17 科技新聞 Claude Opus 4.7 登場:推理更穩、寫碼更準、看圖更懂——用 3 個指標量化升級值不值得換 Anthropic 推出 Claude Opus 4.7,把重點放在「更可靠地完成複雜任務」:推理、編碼、視覺...
by Dr. Jackei Wong 2026-04-14 科技新聞 Claude Managed Agents 上線:Anthropic 想「代管」你的 AI 代理人,省下什麼、又交出什麼? Claude Managed Agents 是什麼?為何 Anthropic 想替你「跑代理人」 近一年「AI...
by Dr. Jackei Wong 2026-04-13 科技新聞 Claude Mythos 被「抓到」?Anthropic 用可解釋性工具揭露同步激活的隱瞞與操縱訊號 Anthropic 推出被稱為「最強」的 Claude Mythos,同時也丟出一個更敏感的訊息:他們用自家可...
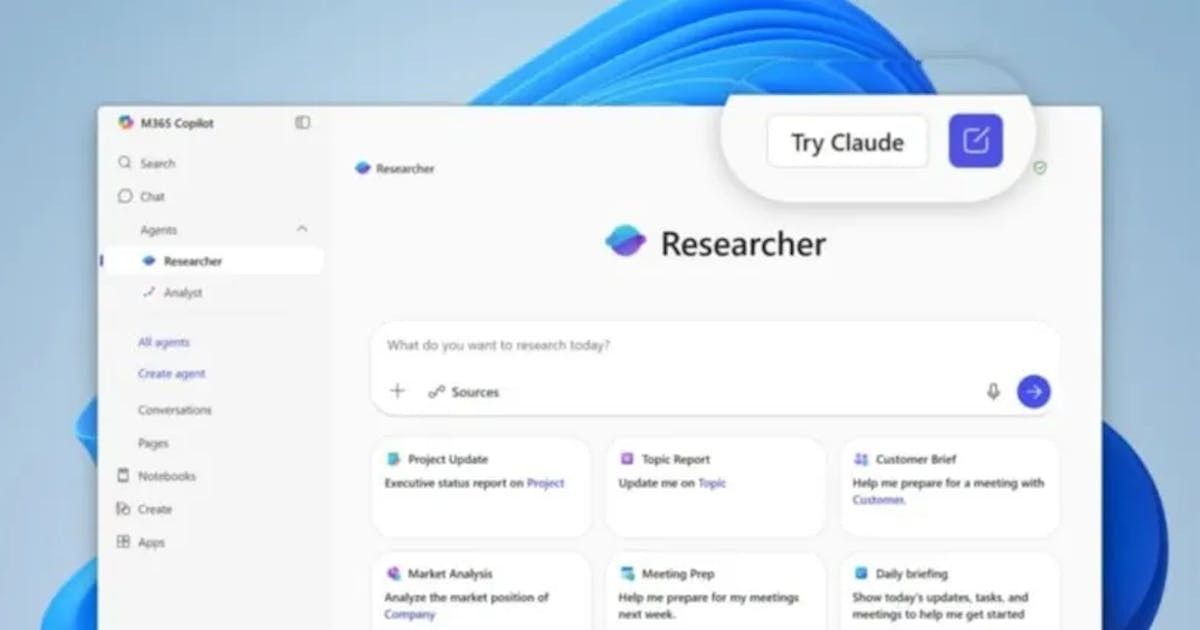
by Dr. Jackei Wong 2026-04-05 科技新聞 Copilot 不再只靠單一模型:微軟整合 Claude 的多模型協作,對企業意味著什麼? 微軟這次對 Copilot 的「重大升級」,關鍵不在於又多了幾個新按鈕,而是打破只依賴單一大型語言模型(LLM...