by Dr. Jackei Wong 2026-04-17 科技新聞 Claude Opus 4.7 登場:推理更穩、寫碼更準、看圖更懂——用 3 個指標量化升級值不值得換 Anthropic 推出 Claude Opus 4.7,把重點放在「更可靠地完成複雜任務」:推理、編碼、視覺...
by Dr. Jackei Wong 2026-04-11 科技新聞 Meta「Muse Spark」多模態 AI 進駐 IG、FB:創作者與行銷人該怎麼用、要注意什麼? Meta 推出全新多模態 AI 模型「Muse Spark」,並宣告將能力直接帶進 Instagram(IG)...
by Dr. Jackei Wong 2026-04-08 科技新聞 微軟一次推出文字、語音、影像三大 AI 模型:企業與開發者該怎麼選、怎麼用? 微軟近期正式宣布自家 文字、語音、影像 三種核心 AI 模型同步上線,等於把「能寫、能聽說、能看」的能力一次補...
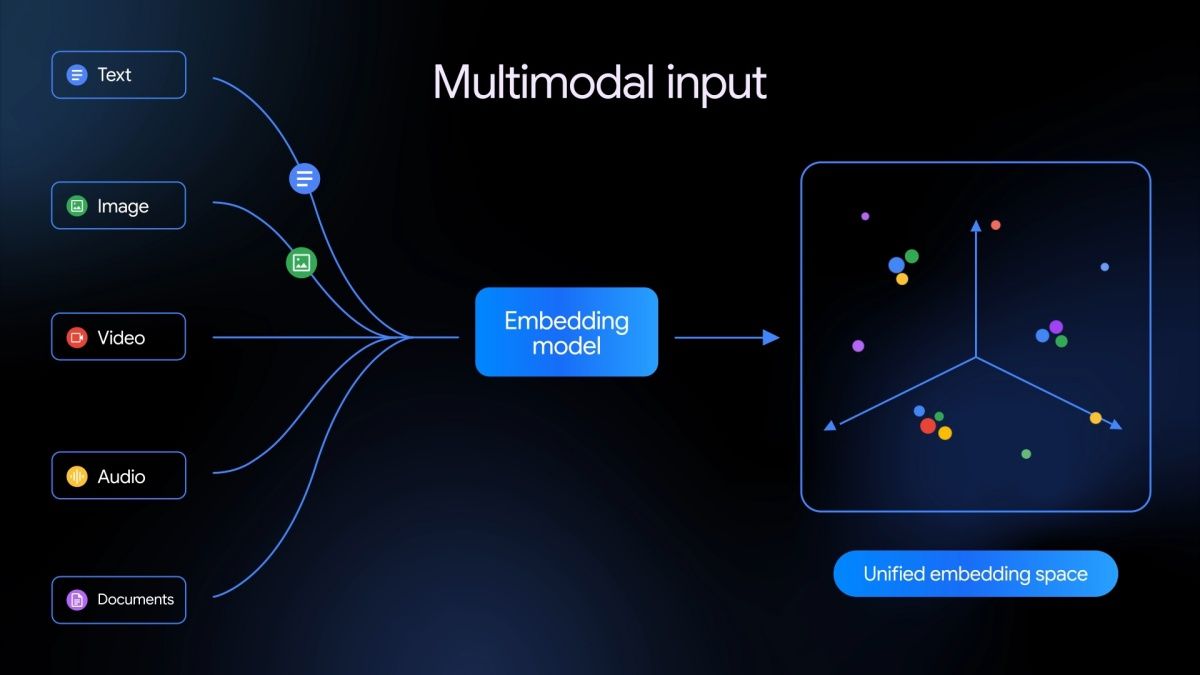
by Dr. Jackei Wong 2026-04-03 科技新聞 Gemini Embedding 2 來了:原生多模態嵌入如何讓「圖像、影音、語言」真正用同一套語義對齊? Gemini Embedding 2 的關鍵:把「看得懂」變成可搜尋、可比對、可檢索 Google 發佈 Ge...
by Dr. Jackei Wong 2026-03-30 科技新聞 文心 5.0 正式版登場:2.4 萬億參數全模態+工具呼叫升級,真能超車 GPT-5 早期版? 文心 5.0 正式版在「規格」之外,真正值得看的是什麼? 百度發布文心 5.0 正式版,最吸睛的兩個關鍵字是「...