
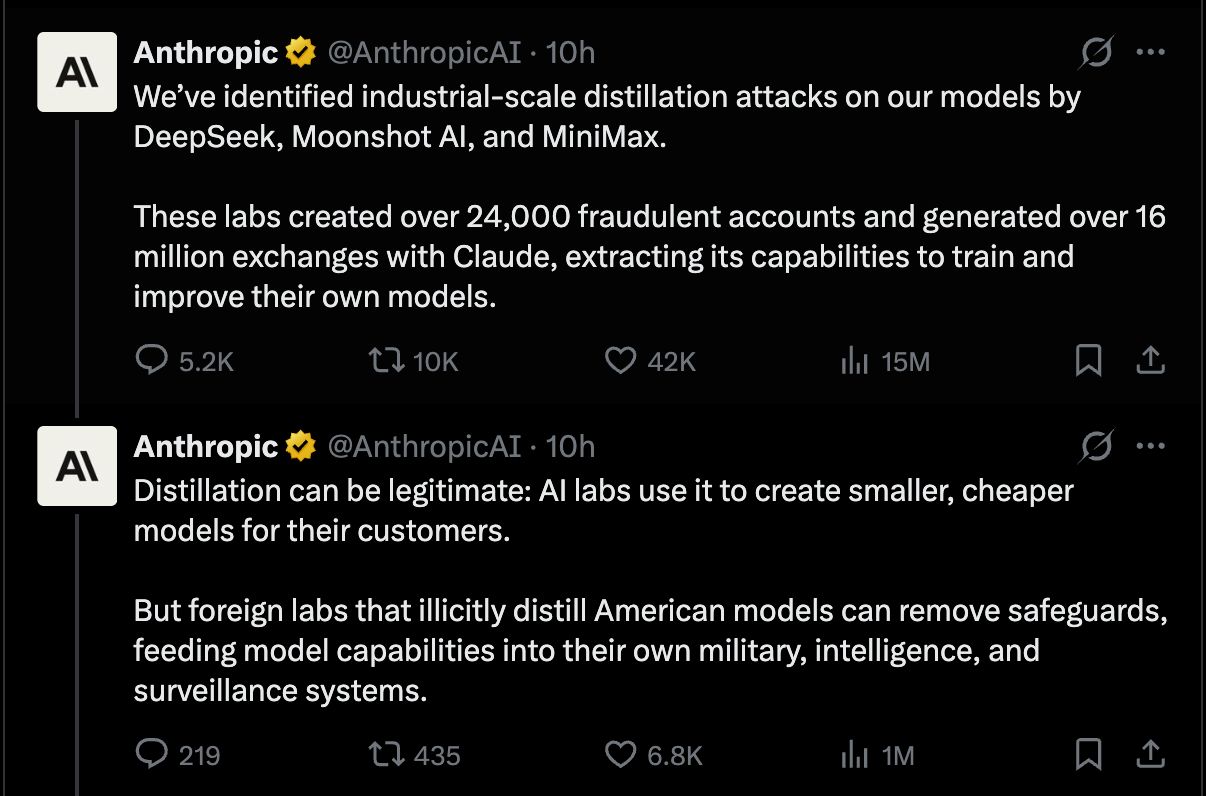
大型語言模型蒸餾正成為當前 AI 戰略版圖上的關鍵詞,特別是在中美大模型競爭與技術擴散的脈絡下。當我們討論中國大型語言模型能否「追上甚至超越」美國前沿模型時,蒸餾究竟是決定性武器,還是被誇大的助攻工具,是一個值得冷靜拆解的問題。
本文聚焦於一個核心提問:蒸餾對大型語言模型的真正影響有多大?
什麼是大型語言模型蒸餾?從「知識轉移」到「合成資料」
在工程實務中,「蒸餾」已遠遠超出教科書中狹義的知識蒸餾定義。如今談的大型語言模型蒸餾,大致包含以下幾層意義:
- 使用更強模型的輸出,去訓練較小或較弱的模型
- 大量生成高品質合成資料(synthetic data),再用來微調或後訓練
- 在特定能力上進行「能力搬運」,例如推理、Agent 行為、工具調用等
換句話說,蒸餾已經不只是「壓縮一個模型」,而更像是用算力把一部分模型能力轉成資料資產,再讓自己的模型去學。
在當前 LLM 開發流程中,蒸餾與合成資料的重要性體現在:
- 補足人類標註資料的成本與稀缺
- 快速試驗新能力(如長鏈推理、複雜工具編排)
- 讓中型模型在特定場景逼近或超越巨型模型表現
也因此,當談到中國大型語言模型的突飛猛進時,外界自然會把目光聚焦到:這些模型到底從美國前沿 API 蒸餾了多少能力?
蒸餾操作的真實規模:數十億還是數千億 Tokens?
近期有國際公司公開指出,多家中國實驗室透過 API 大規模請求其模型,用於訓練自家大模型。粗略估算,部分團隊透過這類操作累積的合成資料規模,可能達到 數百億到數千億 Token 等級,主要集中在:
- 推理與思考鏈(chain-of-thought)
- Agent 行為與工具使用
- 程式碼生成與資料分析
- 多模態與電腦使用場景
如果你熟悉當前開源與商業模型的訓練配置,會知道這個數字並不小。許多針對指令微調(SFT)的資料集只有數十億級別,增加一個數量級的高品質合成資料,確實可能帶來顯著提升。
然而,這裡有兩個關鍵現實:
- 蒸餾量級仍然只是全流程的一部分
領先實驗室在預訓練與 RL 階段投入的總 Token 量與算力,遠遠超過這些蒸餾資料。蒸餾能顯著影響「後訓練」表現,但往往難以完全彌補預訓練與 RL 差距。 -
單看 Token 數量,是一種非常粗糙的衡量方式
如果只是「把老師模型的輸出直接丟進訓練管線」,甚至可能適得其反。資料與原有語料、對齊策略之間的微妙互動,經常讓學生模型在某些能力上倒退。
因此,要理解中國大型語言模型蒸餾的真實效果,不能只看「Token 總量」,而要更精細地看「在哪些能力上、用什麼方式蒸餾」。
為何蒸餾效果「鋸齒化」?不是每一筆合成資料都值得
在實際操作中,大型語言模型蒸餾呈現出高度「鋸齒化」(jagged)的效益曲線:
- 某些任務上,少量高品質蒸餾資料就能大幅提升表現
- 但也常見「加了更多老師輸出,結果反而變差」的情況
造成這種現象的原因包括:
- 能力錯配:老師模型在某類任務上風格或偏好與學生模型的預訓練分佈差異過大
- 標註噪音與風格漂移:大規模合成資料帶來不一致的推理風格與回覆模式
- 資料混排策略不佳:與人類標註數據或其他合成數據混合時比例失衡
這使得蒸餾不再是「多多益善」的單純疊加,而更接近一個高難度的研究與工程優化問題。真正的技術門檻,在於:
- 如何選擇要蒸餾「哪一種能力」
- 如何設計 Prompt 與任務模板產生合適的輸出
- 如何在訓練中權衡這些資料與原始語料、RL 訊號
中國大型語言模型團隊在這方面很可能投入了大量創新,因為這是他們在算力受限情況下,為數不多可以「放大」外部模型能力的槓桿。
蒸餾是捷徑,但真正的戰場在算力與強化學習
從產業結構來看,大型語言模型蒸餾之所以如此吸引人,有一個顯而易見的理由:
要繞過算力瓶頸,蒸餾比走硬體管道容易太多。
對於受限於 GPU 供給或出口管制的團隊來說:
- 租用或繞道使用國外 API,遠比取得大量實體 GPU 容易
- API 消費是「按需付費」,不需要一次性砸下巨額硬體投資
- 可以快速迭代蒸餾策略,而不用長時間鎖死在一次大規模訓練實驗上
然而,這種優勢正在被一個趨勢稀釋:最強的前沿模型越來越依賴大規模強化學習(RL)與在線生成。
在 RL 對齊與推理強化中:
- 生成成本成為訓練中的主角
- 大部分生成必須來自「正在訓練的那個模型本身」(on-policy)
- 外部老師模型的輸出,能提供的多是輔助訊號或離線數據,而非主體訓練資料
也就是說,當模型前沿越來越建立在 RL 基礎上時,單純依賴 API 蒸餾就更難真正複製頂級模型的完整能力結構。
這一點對中國大型語言模型尤其關鍵:即使合成資料與蒸餾做得再極致,如果在 RL 及其算力投入上存在明顯落差,最終的能力差距仍然很難完全抹平。
「效率神話」與中國大模型的真實競爭力
有一種常見敘事是:中國大型語言模型實驗室比西方實驗室「高效許多」,能用更少算力做到相近表現,蒸餾則是關鍵武器之一。
這種說法只對了一部分:
- 在 GPU 受限、成本壓力更大的環境下,中國團隊確實被迫更重視效率
- 也因此在蒸餾、合成資料、精細調參上,往往更積極嘗試各種技巧
但如果把整個研發體系拉長來看:
- 頂級人才的分佈已相當全球化,人才密度差距並不懸殊
- 真正拉開差距的,往往是長期穩定的算力投入、資料積累、以及 RL 基礎設施
- 基準測試(benchmark)選擇與宣傳策略,也會放大表面上的「追平」感
因此,把中國大型語言模型的快速追趕,全部歸功於蒸餾,是一種過度簡化。蒸餾重要,但它更像是「放大器」:如果基礎管線、資料工程、RL 系統已經足夠扎實,蒸餾帶來的收益才能真正被放大。
對實驗室與企業的實務建議:如何聰明使用蒸餾?
如果你在規劃自家中文大模型或企業內部模型策略,可以從以下幾個角度思考蒸餾的角色:
1. 明確「為何」而蒸餾,而不是盲目跟風
- 你是想提升特定任務(例如程式碼、代理、工具編排)?
- 還是想改善整體對話品質與對齊?
- 抑或是希望用蒸餾來壓縮模型、降低推理成本?
不同目標需要完全不同的蒸餾設計與評估指標。
2. 把蒸餾當作「研究專案」,不是簡單工程任務
有效的蒸餾通常需要:
- 設計多樣化的高信號 Prompt 模版
- 探索不同老師模型組合,而非單一來源
- 做嚴格的 A/B 測試與消融實驗,避免「越學越糟」
沒有這些步驟,昂貴的 API Token 可能只是換來一堆無法真正用於生產的合成資料。
3. 與 RL 與資料策略一體化設計
蒸餾不應與 RL、指令調教(SFT)、預訓練完全分離思考,而應納入同一個整體設計中:
- 哪些能力適合用蒸餾打底,再透過 RL 微調?
- 哪些任務反而應該直接依賴人類反饋或可驗證獎勵?
- 如何在訓練日程中安排蒸餾與 RL 的順序與比例?
這些決策,往往比「總共蒸了多少 Token」更決定最終成敗。
4. 對政策與合規風險保持清醒
隨著更多公司開始關注「蒸餾攻擊」與合約條款,依賴外部 API 蒸餾的策略,將面臨愈來愈多:
- 法律與合規的不確定性
- 服務提供方動態調整政策、封鎖或限制使用的風險
- 模型供應鏈地緣政治化的額外變數
長期而言,任何嚴肅的大模型研發者,都必須思考:如果有一天外部蒸餾通道被完全關掉,我們的技術路線是否仍然站得住腳?
結語:蒸餾重要,但不是中美大模型勝負的決勝點
綜合來看,大型語言模型蒸餾對中國 LLM 的確具有實質影響:
- 它讓受限於 GPU 的團隊,能更快在特定能力上縮短差距
- 它為全球模型研發者,提供了低門檻放大算力的「軟性捷徑」
- 它推動了合成資料與資料工程成為新一輪競爭焦點
但同時,我們也必須清楚認識到:
- 蒸餾本身效益高度不穩定,操作不慎反而會拖累模型
- 在 RL 逐漸成為頂級模型核心的時代,單靠蒸餾難以真正複製前沿能力
- 真正決定中美大型語言模型差距的,仍然是長期算力投入、資料積累與 RL 基礎設施
對企業與實驗室而言,最佳策略不是「神話化蒸餾」,也不是「完全忽視蒸餾」,而是:
把蒸餾當作整體 AI 戰略中的一個重要模組,
與資料、算力、RL、產品場景共同設計,
讓它在正確的地方放大你的優勢,而不是遮蓋你的短板。
如果你正在規劃下一代中文大模型,現在正是檢視蒸餾策略的好時機:盤點你真正需要的能力、可長期掌握的算力,以及願意承擔的合規風險,然後決定——哪一部分要靠蒸餾加速,哪一部分必須自己走完全程。
#大型語言模型蒸餾 #中國大模型 #AI蒸餾 #強化學習 #合成資料
追蹤以下平台,獲得最新AI資訊:
Facebook: https://www.facebook.com/drjackeiwong/
Instagram: https://www.instagram.com/drjackeiwong/
Threads: https://www.threads.net/@drjackeiwong/
YouTube: https://www.youtube.com/@drjackeiwong/
Website: https://drjackeiwong.com/


