by Dr. Jackei Wong 2026-02-03 科技新聞 真人社群媒體崛起:生物特徵驗證如何重建AI時代社群平台信任與隱私 真人社群媒體正成為科技業下一個高風險賭注。當充斥機器人帳號與假內容的社群平台逐漸失去信任,主打「只允許真人」的...
by Dr. Jackei Wong 2026-02-01 科技新聞 SpaceX 估值8000億美元:AI、太空科技與OpenAI新創估值戰全方位解析 人工智慧與太空科技的估值戰正進入白熱化階段,而 SpaceX 估值 8000 億美元 的傳聞,無疑把這場新創競...
by Dr. Jackei Wong 2026-01-31 科技新聞 AI 安全準備:為何企業需要 Head of Preparedness、風險治理與心理健康框架? AI 安全準備正在成為生成式 AI 時代最關鍵的議題之一。當大型模型能力急速提升,企業開始意識到,沒有「AI...
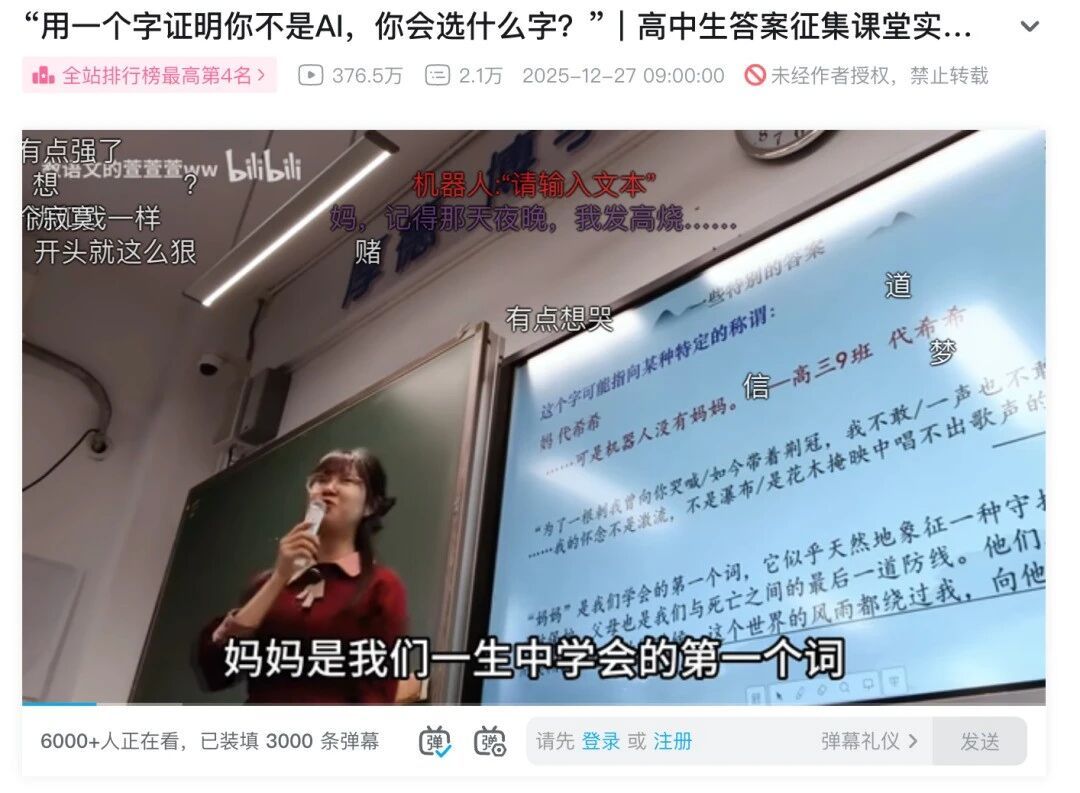
by Dr. Jackei Wong 2026-01-29 科技新聞 用一個字證明你不是AI:生成式人工智慧時代的人性與情感價值解析 在生成式人工智慧快速滲透的今天,「用一個字證明你不是AI」這樣的提問之所以在網路上流傳,背後其實是我們對人性價...
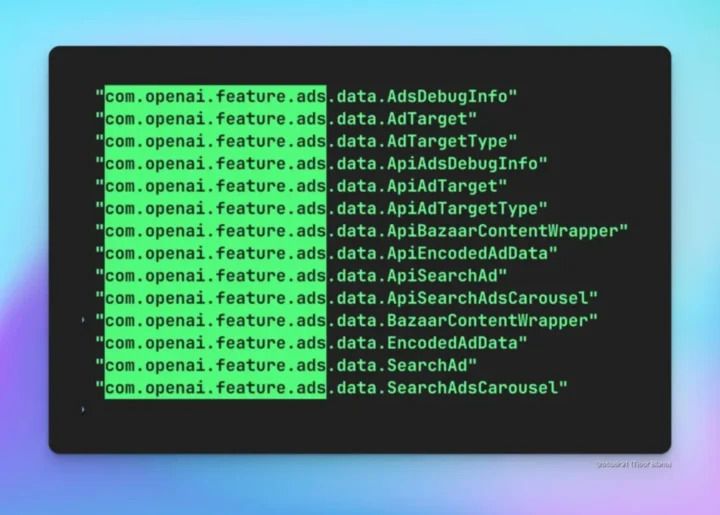
by Dr. Jackei Wong 2026-01-25 科技新聞 AI 廣告攔截器:2026 年守護生成式 AI 搜尋與隱私的關鍵武器 生成式 AI 正在快速滲入搜尋、辦公、購物與娛樂服務,然而真正該被討論的,是「AI 廣告攔截器」何時出現,而不...
by Dr. Jackei Wong 2026-01-24 科技新聞 2026 年新手必學|8 個真正「零門檻」的免費 AI 課程推薦 人工智能(AI)已經不再只是工程師或研究人員的專利。無論你是上班族、學生、創作者,甚至只是單純對 AI 感到好...
by Dr. Jackei Wong 2026-01-23 科技新聞 ChatGPT 年齡預測:AI 兒少保護、內容分級與隱私風險的新時代 AI 兒少保護的新門檻:ChatGPT 年齡預測 功能代表什麼? ChatGPT 年齡預測 功能的推出,標誌著...
by Dr. Jackei Wong 2026-01-22 科技新聞 ChatGPT 校園授權席捲美國大學:生成式 AI 戰爭、風險與教育治理關鍵解析 ChatGPT 校園授權正以驚人速度改變美國高等教育的版圖,OpenAI 則在背後推動一場安靜卻激烈的「校園...
by Dr. Jackei Wong 2026-01-20 科技新聞 OpenAI 認證:用 AI Foundations 快速縮小 AI 技能差距與職涯落差,抓住未來就業關鍵門票 OpenAI 認證正成為企業縮短 AI 技能差距的關鍵工具。面對生成式 AI 的爆炸性成長,OpenAI 推出...
by Dr. Jackei Wong 2026-01-19 科技新聞 AI 自動化工作:OpenAI 點名最先被取代的三大白領產業 AI 自動化工作正在加速改變白領職場,也正在重塑「哪種工作最容易被 AI 取代」的順位。當 OpenAI 高層...
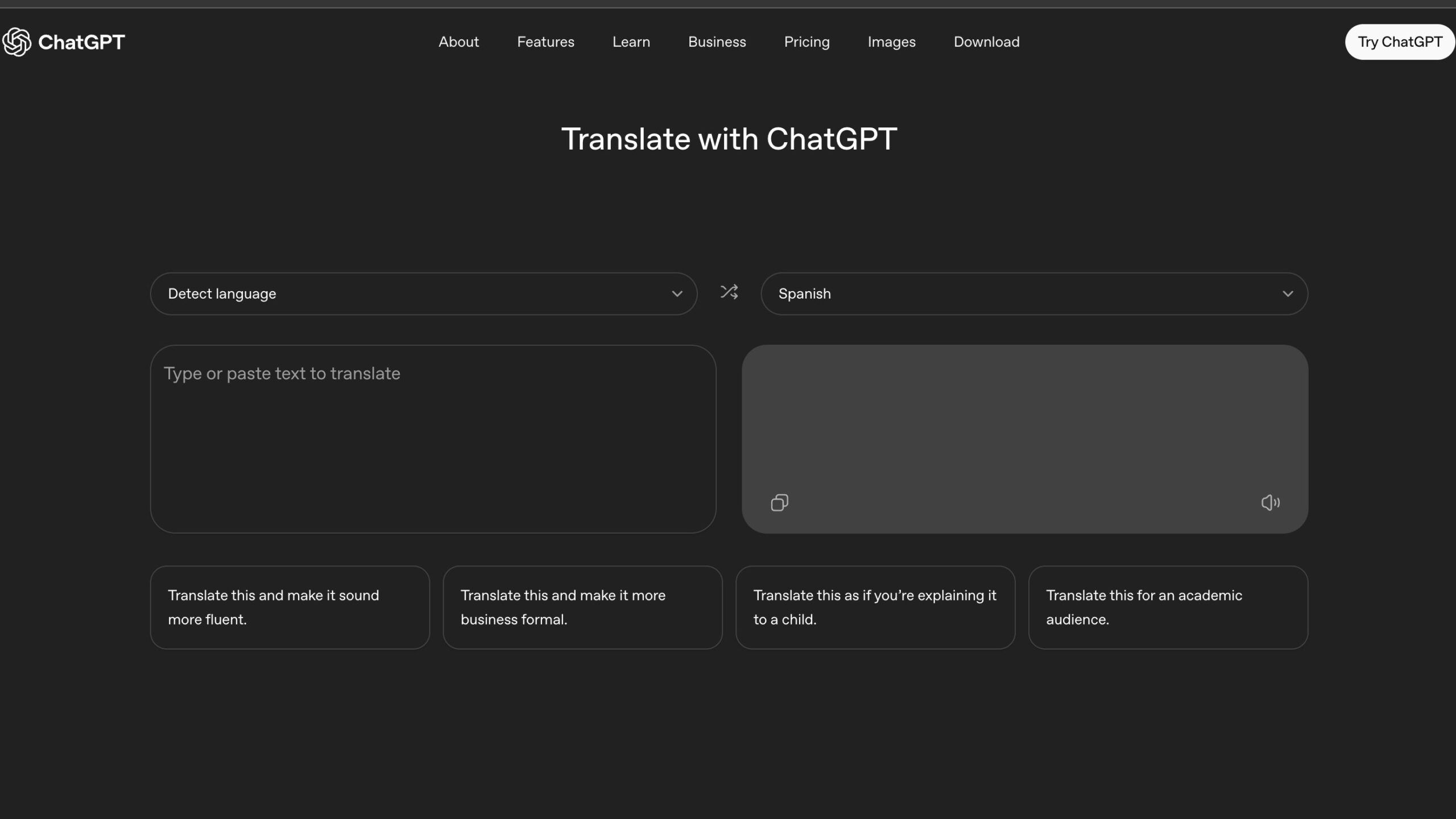
by Dr. Jackei Wong 2026-01-18 科技新聞 ChatGPT 翻譯 vs Google 翻譯:AI 翻譯工具完整比較、優缺點、使用情境與選擇建議全攻略懶人包 ChatGPT 翻譯正在改寫我們對線上翻譯工具的想像。隨著 ChatGPT Translate 正式成為獨立翻...
by Dr. Jackei Wong 2026-01-17 Uncategorized, 科技新聞 ChatGPT Go 全球推出|香港能不能用?付費方案比較、VPN 開通攻略 OpenAI 最新推出的 ChatGPT Go 訂閱方案已 全球上線,旨在讓更多用戶以更低成本體驗進階 AI...