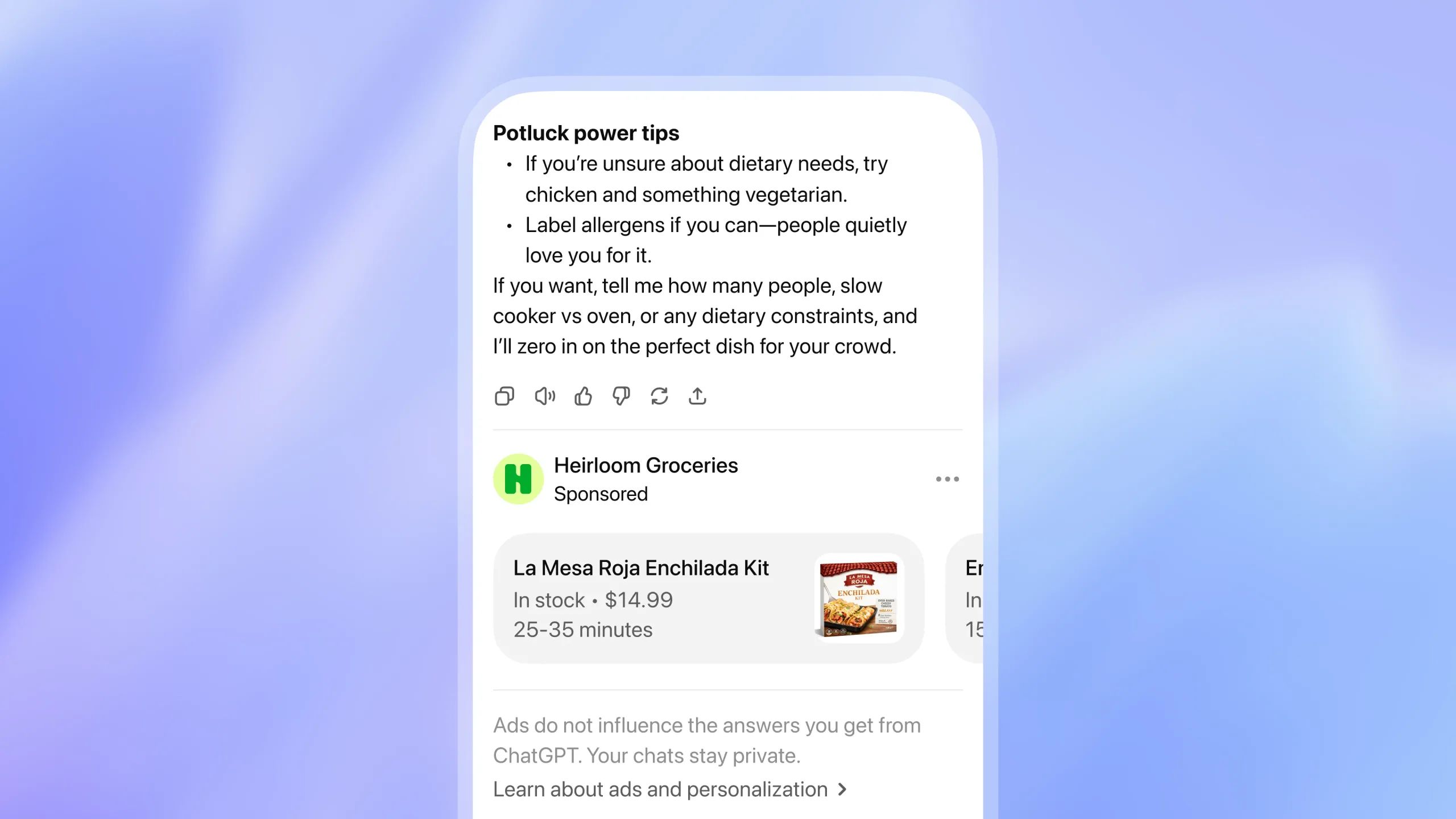
by Dr. Jackei Wong 2026-05-25 科技新聞 ChatGPT免費版變廣告平台:你的對話紀錄就是個人化廣告的燃料 OpenAI正在為ChatGPT免費版鋪設廣告系統,核心轉折在於:免費用戶的對話內容將被用於個人化廣告投放。這...